
Introducing scorecards for AI agent evaluation

Why AI agent performance evaluation matters
As AI agents become increasingly central to customer service operations, a few key questions remain:
How do you evaluate the quality of an AI agent's responses like you would a human agent? How can you ensure quality and accountability in real time to mitigate risks?
Without visibility into how your AI customer service performs, product and support teams risk deploying AI agents that provide irrelevant answers, sound robotic, or worse—frustrate and drive away customers.
According to recent research, a 1% error rate in AI agent responses can accumulate over multi-step processes—leading to a possible 63% failure probability.
At Sendbird, we’re solving this QA challenge with our new feature: the AI agent scorecard.
Now you can evaluate the conversations of AI agents for quality, accuracy, readability, and tone—right within your AI agent dashboard—to ensure transparency, reliability, and performance at scale.

8 major support hassles solved with AI agents
What is the Sendbird AI agent scorecard?
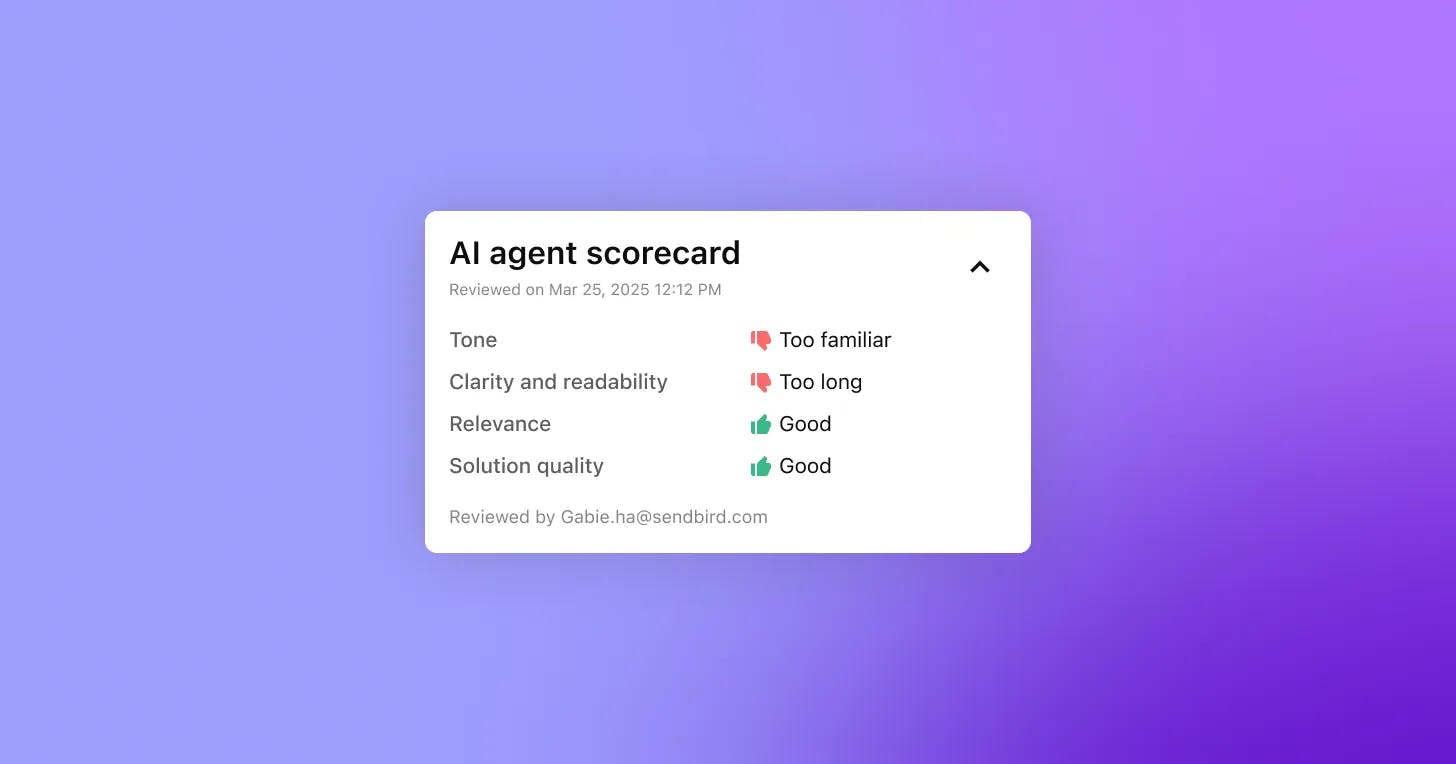
The AI agent scorecard enables you to automatically score and review individual AI-led conversations across key quality categories, including:
Tone: Was the AI agent’s tone professional and appropriate?
Readability: Were responses clear and easy to read?
Response relevance: Was the AI’s answer accurate and on-topic?
Solution quality: Did the AI solve the user’s problem?
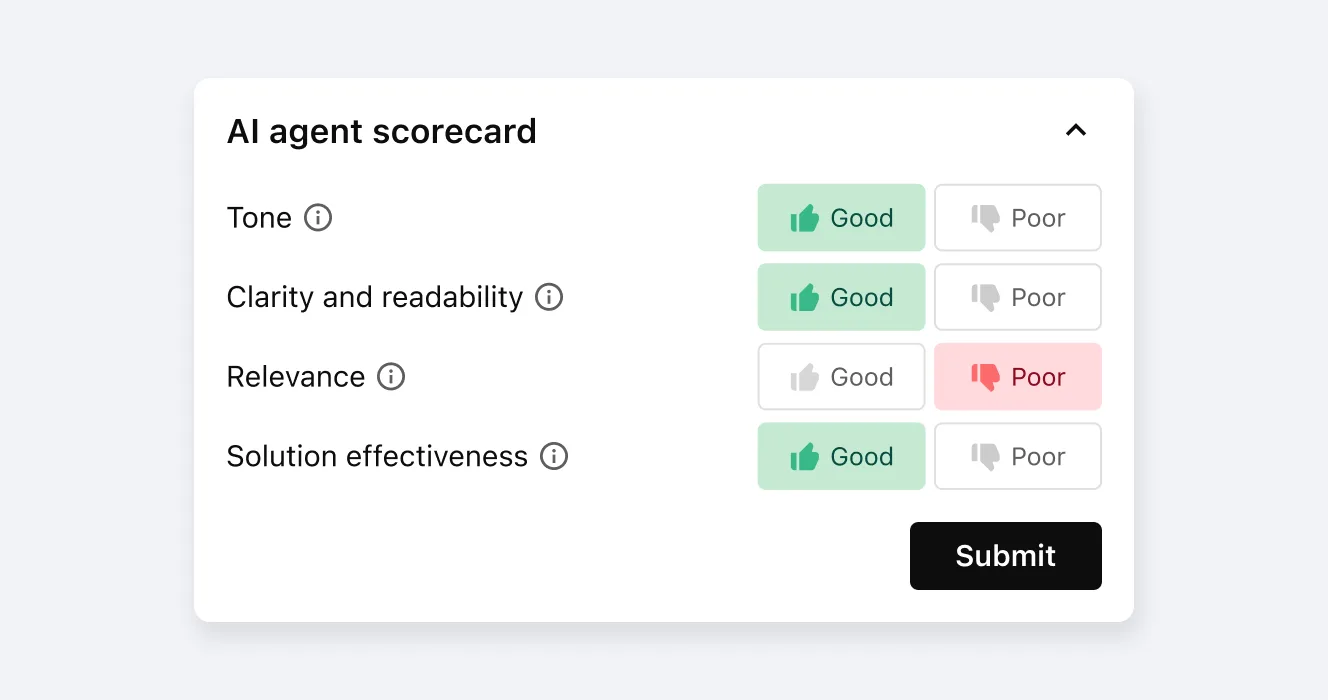
Each category can be rated as Good 👍 or Bad 👎, with the option to provide additional feedback when responses are rated negatively—just like QA tools for human agents.
Just like with human agents, good AI customer care doesn’t happen on its own. You’d never hire a support rep without providing onboarding, training, and ongoing performance coaching. And so, building an effective AI agent doesn’t stop at launch.
The AI agent scorecard serves as a continuous performance evaluation for AI agents. It enables regular human oversight (HITL) and conversation QA review, making it essential to deploy AI for customer support that’s not just effective, but transparent, compliant, and reliable at scale.
How does the AI agent scorecard work?
Located in your AI agent dashboard, the AI agent scorecard can be viewed in one of two ways:
Conversation list view: Next to each closed conversation, a new column makes it easy to review and score conversations.
Conversation detail view: Scorecards appear within each individual conversation (once it closes) for deeper context.
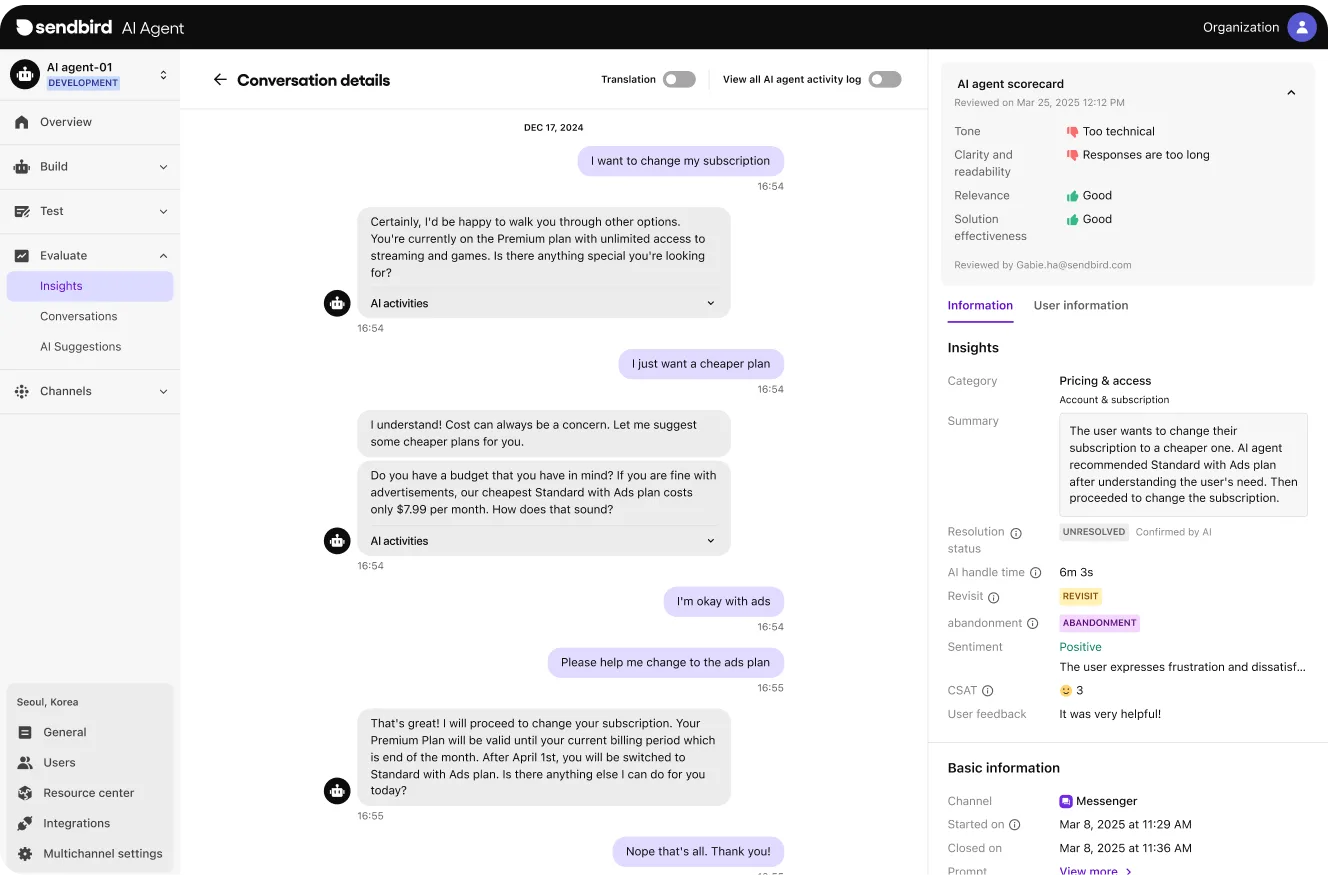
AI agent scorecards only appear once conversations are closed, keeping the experience streamlined and focused.
A simple QA rating system with optional custom feedback
Say a category of agent performance is rated “Bad.” Admins can select from preset reasons (e.g., “Responses are too long” or “Solution doesn’t address the problem”) or add custom comments for improvements. This mirrors industry best practices and is inspired by tools like Intercom.
Keyboard shortcuts and streamlined workflows also let QA teams power through reviews efficiently.
One scorecard per conversation
Rather than overwhelming users with per-message feedback, each conversation is evaluated holistically, aligning with how teams assess human agent performance.
How QA scores improve AI support agent performance
While these performance scores won’t directly change the AI agent’s behavior, they do offer crucial insights to optimize its performance right away.
Conversations scored as “Good” can be used as few-shot examples to improve AI agent prompts or responses. “Bad” scoring can highlight specific issues with tone, accuracy, relevance, or readability to guide improvements:
Unprofessional tone → AI prompt or AI model parameters adjustments.
Poor readability → communication style tuning.
Irrelevant answers → updating the knowledge base or adding new snippets.
As feedback accumulates, teams can track patterns to fine-tune the agent’s behavior with data—not guesswork.
From feedback to continuous learning
Rated conversations can also be added to the AI agent testset (or future agent testsets). This helps create a baseline of good and bad responses, enabling continuous AI agent evaluation and benchmarking that agents can themselves refer to as they decide on the most appropriate action in the moment.
This data serves as the foundation for a closed feedback loop in which AI agents self-improve over time. Scorecards play an increasingly important role in agentic AI performance and a critical element for omnichannel AI customer service.

Leverage omnichannel AI for customer support
Meeting AI agent QA enterprise standards
For enterprises deploying AI concierges at scale—whether to improve customer service, engagement, or operations—this oversight and accountability feature for AI agents brings peace of mind. You can now:
Audit AI agent performance just like you would for human agents
Spot weaknesses in tone, clarity, and accuracy
Drive iterative improvements with real-world data
Whether you're managing thousands of daily support conversations or refining your AI customer service experience, the AI agent scorecard helps you build trustworthy, high-performing AI agents.
Ready to QA your AI agent? Sendbird’s AI agent QA scorecard is now available for all customers using our generative AI capabilities. Contact your CSM or our sales team to learn more.












