DeepSeek vs. OpenAI: What Mixture of Experts & Chain of Thoughts changed


DeepSeek proved everyone wrong
For years, AI has been a game of brute force. The bigger the model, the smarter it was supposed to be. If you had a myriad of GPUs and hundreds of millions of dollars, you could build the best AI. Big Tech bet everything on this logic. OpenAI locked its models behind APIs. Meta gave researchers access to LlaMA, but by construct, the large language model (LLM) could only be used as is—no one could afford to modify, or fine-tune the model. In the meantime, Nvidia’s stock soared as every AI company scrambled to buy more GPUs to train their next model.
In January 2025, DeepSeek did something unexpected.
What is DeepSeek?
DeepSeek is a Chinese artificial intelligence company founded in 2023 and backed by hedge fund High-Flyer. It develops open-source large language models. For only $5 million, it built an open-sourced AI model that competes with large language models like GPT-4o and LLaMA4. Instead of relying on sheer size, they used new architectures and techniques—Mix of Experts (MoE), Distillation, and Chain of Thought (CoT)—to create a cheaper AI that also performs incredibly well.
DeepSeek’s chatbot made waves in the U.S., becoming one of the top-rated free apps on the Apple App Store. This unexpected surge in popularity shows that DeepSeek isn’t just winning over researchers and developers—it’s reaching everyday users at scale. it's establishing itself as a real competitor to OpenAI's ChatGPT.

Let’s review the technological advancements DeepSeek leveraged and revealed, and their implications for the field. Let’s remember first what LLMs are.

Boost CSAT with proactive AI customer service
How large language models (LLMs) work and DeepSeek challenges the approach
To understand DeepSeek’s impact, it helps to break down how large language models (LLMs) work. LLMs like OpenAI’s GPT, DeepSeek Vx, and LLaMAx are built using Transformer-based neural networks. These models are trained using vast amounts of text data to predict the next word in a sentence.
Training involves massive resources to process internet-scale datasets, refining the AI’s ability to understand and generate human-like text. This approach gave a decisive advantage to companies with unlimited budgets. The AI race over the past few years has centered on building ever-larger models, leading to astronomical training costs:
GPT-4 is estimated to have cost over $100 million to train.
Meta’s LLaMA models required over 100,000 GPUs for training.
DeepSeek challenges this approach with technologies that use significantly fewer resources. Let’s review them.
What is Mixture of Experts (MoE)? LLMs don’t need to be know-it-alls anymore
Mixture of Experts (MoE) is an AI architecture that improves efficiency by dividing a large neural network into specialized sub-networks, or "experts," each trained for specific tasks. This allows for a dramatic reduction in the cost of inferences. Let’s quickly explain how.
Imagine walking into the biggest library in the world. There’s only one librarian, and they insist on answering every question themselves—whether it’s about Shakespeare, astrophysics, or quantum computing. It’s chaotic. The librarian constantly pulls information from a million different sources, spending tremendous energy on each request. Now, picture a second library. This one has specialist librarians—each an expert in their domain. When you ask about astrophysics, you’re sent straight to the astrophysics expert, who knows exactly what you need.
That’s precisely what Mixture of Experts (MoE) does for AI. Most AI models, including GPT and LLaMA, operate like the first library—they force the entire neural network to process every request, no matter how simple. It’s like turning the lights of an entire building no matter the room you’re standing in. MoE changes this by breaking and turning on only certain parts of its model specialized in the domain of the question. When a user asks a question, MoE routes it to the most relevant section of the model, activating, let’s say, 8 billion parameters instead of 672 billion. This efficiency ensures faster responses at a fraction of the computational cost.
This is how DeepSeek-V3 reduces the cost of API calls and inference of ChatGPT. But there is more.

Reimagine customer service with AI agents
What is model distillation? How to shrink AI without killing its intelligence
Model distillation in AI is a technique that trains a smaller language model using a large, more complex one. This approach enables AI to run efficiently on lower-end hardware, making advanced AI capabilities accessible without relying on massive server farms.
The biggest challenge in AI today isn’t just the cost of training—it's the sheer expense of running these models at scale. LLMs with hundreds of billions of parameters demand enormous computing power, which is why API access to these models comes at a premium.
DeepSeek’s approach to distillation upends this model. Instead of relying on brute-force computing, it enhances AI efficiency by making smaller models just as capable. First, a large model generates vast data, producing responses across multiple topics. These responses then serve as training material for a compact model, allowing it to mirror the performance of its larger counterpart without carrying its computational burden.
The impact? A distilled model can run on a single computer rather than an entire data center, allowing businesses and individuals to host their own AI models. This reduces costs, removes dependence on major AI vendors, and opens the door to a new era of AI accessibility—where high-performance models aren’t limited to those with deep pockets.
What is Chain of Thought (CoT)reasoning: Smarter AI at a fraction of the cost
Chain of Thought (CoT) is an AI technique that encourages models to develop and display their reasoning before delivering an answer. Instead of making a blind guess, the AI writes out its thought process, ensuring a logical approach and accuracy in its response. During training, the model is rewarded both for producing a structured chain of thought and for arriving at the correct answer. This reinforcement learning (RL) approach has produced remarkable results—boosting accuracy beyond models like LLaMA and ChatGPT while significantly reducing training costs.
Traditional AI models predict words one at a time, like trying to complete a sentence without fully understanding its meaning. This approach works for many queries but struggles with complex reasoning tasks—such as solving multi-step math problems, following intricate instructions, or answering logic-based questions. To overcome this issue, models like DeepSeek-R1 and GPT-4o leverage Chain of Thought (CoT) reasoning.
DeepSeek vs OpenAI: How the R1 model is challenging GPT-4o?
DeepSeek-R1 is changing the game in AI because it’s openly showing the world how CoT can achieve world-class performance without massive hand-crafted reasoning datasets. Reinforcement learning only requires small data sets of questions and answers, reducing dramatically the cost and complexity of training. By going open-source, DeepSeek ensures that AI reasoning for exceptional answer accuracy isn’t locked behind corporate paywalls anymore but is available to anyone to build the next-generation models. See below how DeepSeek R1 is able to exceed the performance of OpenAI GTP-4o within a few thousand steps.
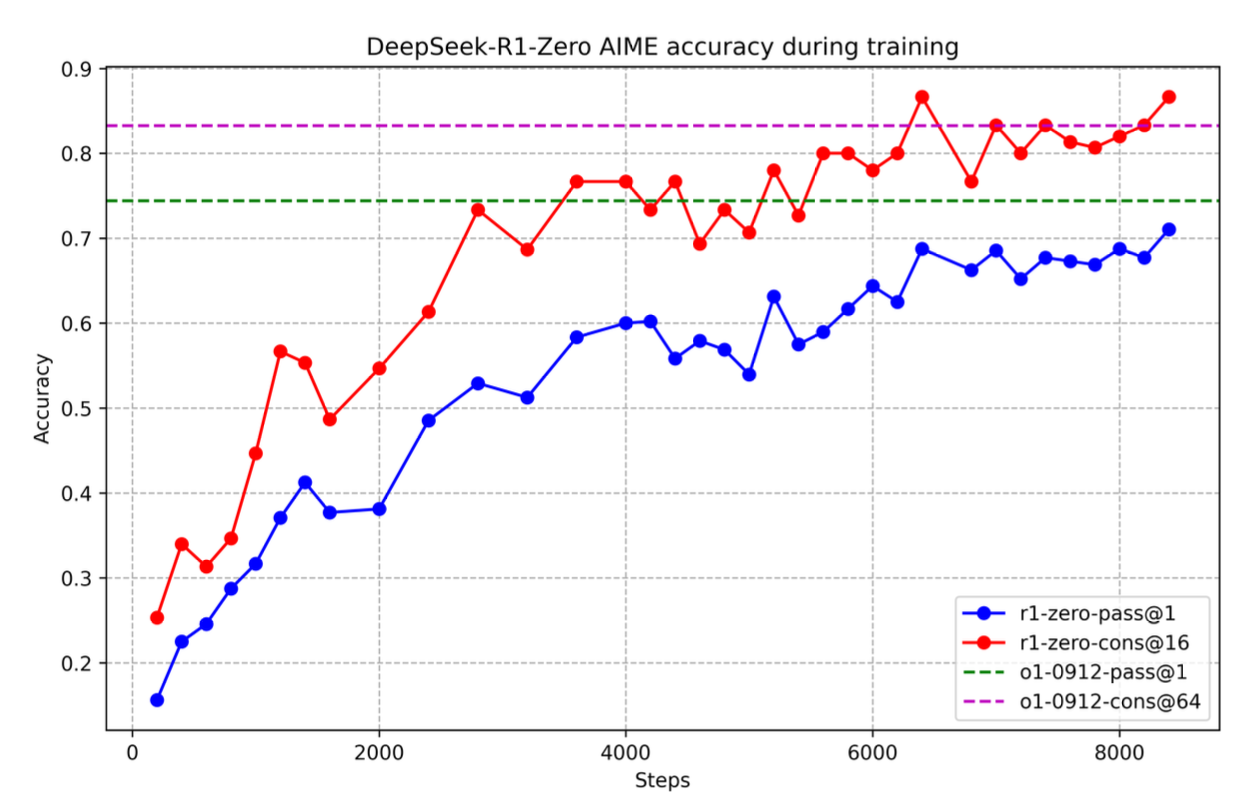
Is DeepSeek putting an end to closed-sourced AI from OpenAI, Anthropic, and Google?
For years, the AI landscape has been dominated by an unshakable belief: only the most prominent companies with the most funding could build powerful AI—OpenAI, Google, and Anthropic. The industry has been shaped by a race for scale, where success was measured in the sheer size of models, the vastness of datasets, and the number of GPUs thrown at the problem.
DeepSeek has shattered that myth, and the industry will be impacted:
Will OpenAI and Google be forced to release more technology to stay competitive?
Will businesses host their AI models instead of relying on expensive cloud-based APIs?
Will Nvidia’s GPU dependence shift away as DeepSeek demonstrates that smaller-scale hardware can achieve cutting-edge results?
DeepSeek’s bold move to go open-source revealed that anyone can tinker seriously with AI without massive infrastructure and resources by going open source. It paved the way for ingeniosity to rival brute-force innovation enabled by billion-dollar investments. We are excited at Sendbird to see how the market will evolve and if businesses will create their proprietary models to power their AI agents.
DeepSeek leveled the playing field. More than a technological shift—it’s a restructuring of power in AI. Is AI now poised to be cheaper, more accessible, and in the hands of researchers, startups, and businesses everywhere? The future will tell, but DeepSeek has changed the game for good.

Harness proactive AI customer support
Frequently Asked Questions (FAQ)
What models did DeepSeek release?
DeepSeek’s rise didn’t happen overnight. Below is a timeline of major DeepSeek model releases:
DeepSeek V1 (January 2024) – A 67 billion parameter model, built as a traditional transformer-based architecture.
DeepSeek V2 (June 2024) – A 236 billion parameter model, introducing multi-headed latent attention and Mixture of Experts (MoE), significantly improving efficiency.
DeepSeek V3 (December 2024) – A massive 671 billion parameter model, incorporating reinforcement learning for even better adaptability and computational efficiency.
DeepSeek R1- (January 2025) – Built on R1-Zero, combining reinforcement learning and supervised fine-tuning to optimize reasoning abilities.
What other models did DeepSeek release?
In addition to its reasoning-focused R-series, DeepSeek has also developed DeepSeek Coder, an open-source code generation model built to rival models like Codex and Code LLaMA. Designed for software development tasks, DeepSeek Coder supports multiple programming languages and has quickly gained traction among developers for its performance and accessibility.
How is MoE different from model distillation?
MoE is an architecture designed to reduce computation during inference. Distillation, on the other hand, is a training technique that compresses knowledge from a larger model into a smaller one to make training more efficient.









