
Enhancing AI agent testing with multi-turn conversations

AI support agents aren’t AI chatbots answering FAQs anymore—they resolve complex issues through conversations and tool action-taking, all while representing your brand. But how do you ensure your AI agents perform in the real world?
Most teams use prompt-level or single-turn testing, which fails to account for tool use, context carryover, or realistic multi-turn flows.
That’s why Sendbird introduces multi-turn conversation testing, a testing framework that evaluates your support AI agent workflows using real-world, end-to-end conversations instead of synthetic prompts.
What is multi-turn conversation testing?
Multi-turn conversation testing evaluates how an AI agent performs across an entire dialogue. It ensures the AI can handle dynamic, real-world conversations that span multiple messages, actions, decisions, and scenarios. This approach simulates complete customer journeys—like resolving an account issue or tracking an order—where context builds with each turn.
By testing multi-turn flows, businesses can detect logic breakdowns, context loss, or inconsistent behavior before going live, ultimately delivering a more reliable and human-like experience to users.
Why is AI agent prompt testing not enough?
Most AI support agent testing strategies today focus on single-turn interactions: one prompt, one response. While helpful in evaluating syntax and style, this method fails to reflect how AI concierges behave in production.
Prompt-level testing can answer if the model is responding, but it can’t answer the following:
Did the AI follow the workflow?
Did it call the right tool?
Was the AI able to maintain context and extract the correct conversation elements?
Did it mirror the behavior of a trained human agent?
These questions demand a testing strategy that goes beyond string-matching. They require an end-to-end evaluation process.

8 major support hassles solved with AI agents
Introducing end-to-end AI agent testing
End-to-end AI agent testing uses collections of real dialogues to evaluate how an AI agent performs across an entire conversation. They allow support teams to measure accuracy, consistency, and tool usage in a realistic workflow.
With Sendbird, you can upload conversation transcripts—between users and human (or AI) agents—and evaluate how closely the AI matches expected performance across an entire exchange, including:
Workflow fidelity
Semantic match to expected responses
Tool-trigger behaviors
API integration coverage
This means you’re no longer testing how the AI responds in theory—you’re testing how it performs in your production context.
Why does End-to-End (E2E) multi-turn conversation testing matter for businesses?
In AI customer service, real value lies in the AI’s ability to handle the unpredictable. End-to-end (E2E) testing ensures your AI agent is ready for production by simulating complete user journeys.
This matters because no two customers behave the same; their journeys vary with products, context, and needs. Without robust E2E testing, blind spots can go unnoticed until they surface in front of customers.
Sendbird’s E2E AI Agent testing gives businesses confidence by replaying actual user-agent dialogues, flagging drifts in behavior, and tracing breakdowns back to their source. This lets companies launch faster, fix better, and protect customer trust—all while continuously growing a library of real-world tests that evolve alongside the business.
How does Sendbird multi-turn conversation testing work?
Step 1. Add a conversation test set
You start by adding a test set, which can be a conversation transcript instead of a static FAQ. The system accepts CSV format or pasted input with Sender and Message columns. Each test is tied to a User ID to simulate realistic tool-triggering and context recall.
This design ensures you’re testing against real customer journeys. It also sets the foundation for reusable datasets as more conversations are logged through the Sendbird AI agent platform.
💡Sendbird tip: Conversations don’t need to be Actionbook-based—but Actionbooks can be created from these tests for future optimization.
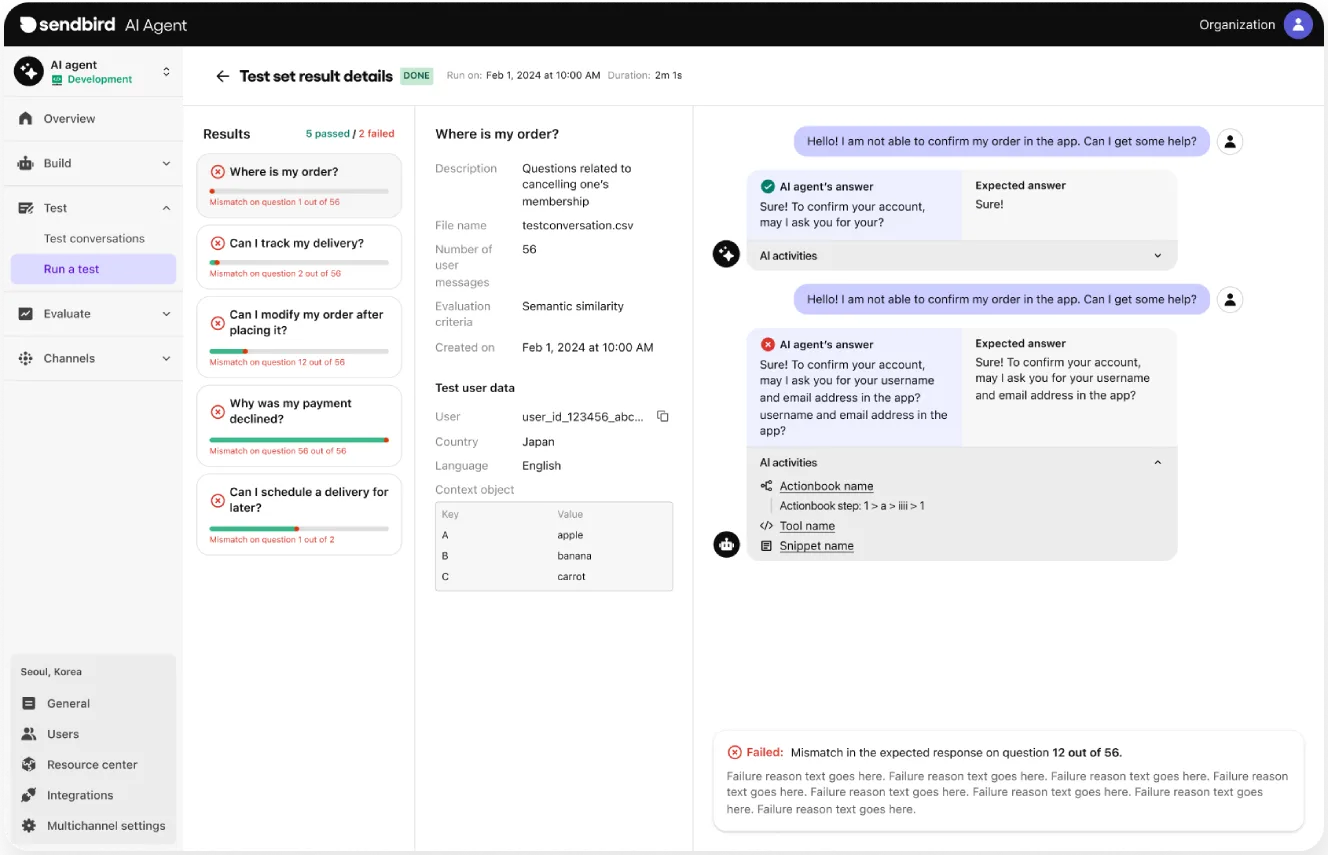
Step 2. Run the test and score the interaction
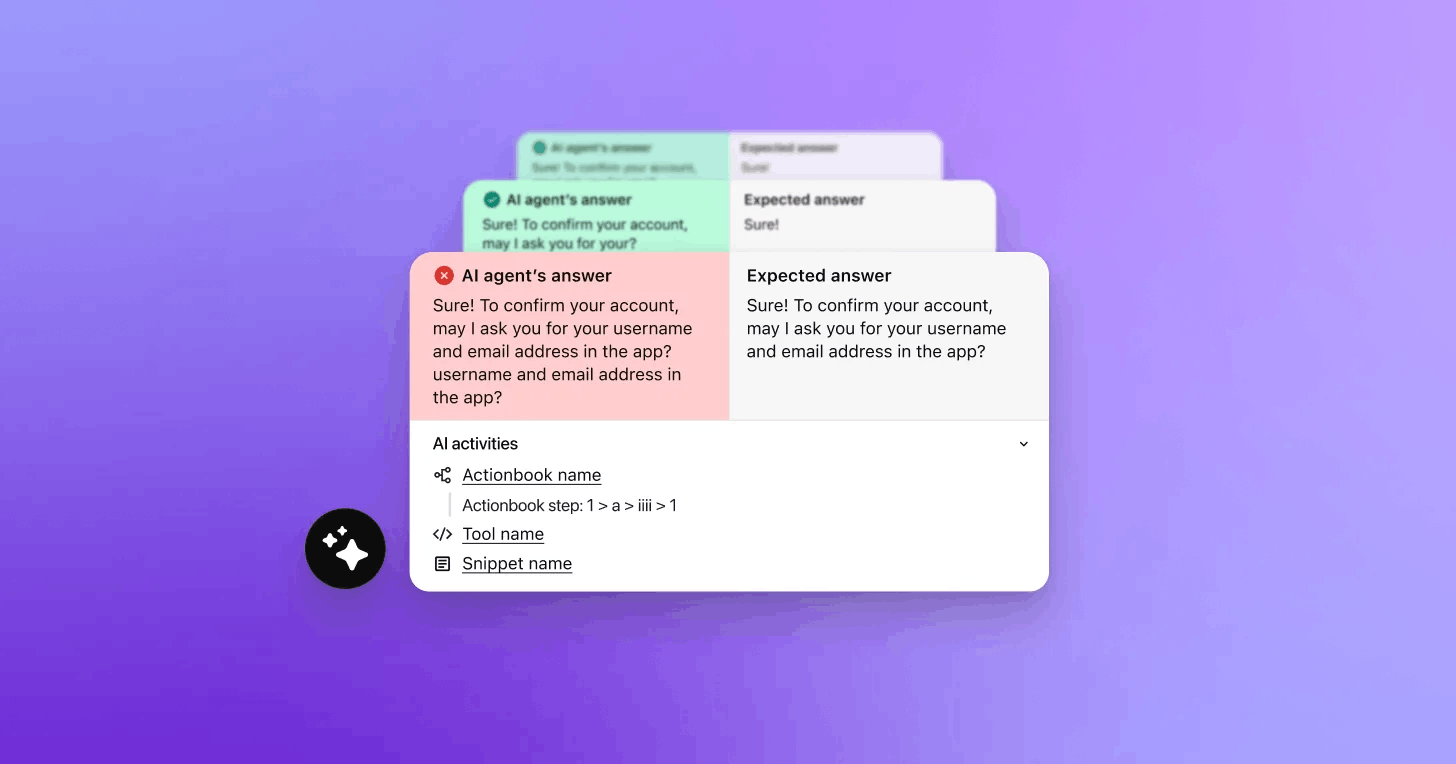
Once a transcript is uploaded, Sendbird compares your AI agent’s output to the reference transcript—turn by turn. Using semantic similarity scoring (based on frameworks like OpenAI’s and Azure’s), each response is evaluated against the expected reply.
If the similarity score falls below your defined threshold, the test fails and highlights the exact turn where the mismatch occurred. You can then see which Actionbook or knowledge base entry was used, making debugging and refinement straightforward.
Step 3. Analyze the results and iterate
After each run, test results are logged, editable, and rerunnable. In the near future, you’ll be able to schedule tests to run on a preset cadence, turning this into a continuous testing pipeline. No more guesswork about whether your AI workflows still behave as expected after a knowledge base update or a model upgrade.

Automate customer service with AI agents
Prompt testing vs. multi-turn conversation testing
Most GenAI QA frameworks rely on artificial prompts or scripted tests. Here’s why Sendbird’s approach for AI customer support is different:
Capability | Traditional prompt testing | Sendbird end-to-end testing | |
Single-turn prompts |
|
| |
Multi-turn flows |
|
| |
Tool usage validation |
|
| |
Real transcript support |
|
| |
Semantic response comparison |
|
| |
Scheduled test automation |
|
|
Whether you’re using OpenAI, Claude, or another LLM, this system evaluates how the AI support agent behaves in your system, not just how well it answers a prompt in isolation.
Trust and safety require AI Agent testing at scale
For enterprises, trust in AI isn’t just about accuracy—it’s about reliability. And because AI support agents scale faster than any human team, they must be rigorously tested. That’s why AI agent quality assurance (QA) is essential.
With Sendbird’s conversation-based end-to-end testing, you can validate beyond the model’s output and check the entire support experience. As conversations accumulate, your QA coverage deepens—turning daily operations into a continuously improving dataset.
If you’re ready to transform your AI support experience, 👉 talk to us; We’re here to help.













