
The complete guide to AI agent evaluation


Evaluating AI agents is crucial to building effective, trustworthy AI systems. AI agents act on behalf of users and businesses with autonomy, making decisions, executing tasks, and interacting with customers. The more agency you give an AI agent, the greater the need for rigorous evaluation to ensure its safe and proper functioning.
AI agent evaluation provides visibility not just into the agent’s outputs, but also the reasoning paths and workflows behind them—enabling transparency, iterative improvement, and the confidence to scale. However, agenic workflows often span multiple tools and touchpoints, so achieving this level of AI observability can be complex—making evaluation a multifaceted challenge.
This guide will walk you through how to evaluate AI agents to ensure their performance and reliability. You'll learn everything you need to turn AI agent pilots into trusted, scalable solutions that drive measurable gains in customer experience (CX) and efficiency, without needless risk.
Specifically, we'll cover:

Build lasting customer trust with reliable AI agents
What is AI agent evaluation?
AI agent evaluation is the process of assessing the performance, reliability, and safety of an AI agent to ensure it meets the goals and ethical standards defined by an organization. The aim is to identify errors in agent logic, improve performance, and ensure the agent operates responsibly and effectively in production. Evaluating AI agents involves testing their abilities on various tasks, as in traditional software testing. However, it also involves added considerations for the behaviors unique to agentic AI.
For example, an event like a “where's my order?" query to an AI support agent triggers an agentic workflow. Even if the final output is a text response, it may be the result of intermediate actions—multi-step reasoning, calling an API, or querying a database with retrieval augmented generation (RAG)—each of which needs to be evaluated separately. Beyond evaluating the final output, it’s critical to assess what the agent knows, what actions it takes, and how it plans actions within its decision-making process.
Beyond assessing task performance and the steps taken to get there, AI agent evaluation must also consider factors like AI trust, safety, compliance, and security. These dimensions are critical in real-world environments, helping ensure agents avoid unsafe behavior, maintain reliability through verifiable outputs, and resist manipulation or misuse. Efficiency is also important. Without monitoring factors like computational cost, organizations risk deploying agents that perform well but drain resources.
Ultimately, an evaluation measures whether the agent is doing the right thing (effectiveness) and how well it's doing it (efficiency). It involves assessing the agent's performance based on functional factors (accuracy, reliability, task completion) and non-functional factors (safety, cost-effectiveness) through a structured process that includes automated testing, simulations, and human-in-the-loop reviews.

5 key questions to vet an AI agent platform
Why is AI agent evaluation important?
AI agent evaluation is important because agents are powered by large language models (LLMs), which are inherently non-deterministic. This means that agents can follow unintuitive paths to achieve their goal, perhaps reaching a correct outcome via a suboptimal process, or failing in subtle ways (which makes debugging difficult).
Without rigorous evaluation, an agent might perform well in basic scenarios but collapse in edge cases or underperform in real-world conditions. AI agents often make complex decisions in dynamic environments, and organizations need to ensure they are effective, efficient, and reliable. Otherwise, organizations risk eroding trust with users and stakeholders due to unsafe, irresponsible AI.
As AI systems become more advanced and widespread, robust evaluation becomes critical for several reasons:
Key benefits of AI agent evaluation
Validate performance: Confirm that the agent performs its defined goals (like resolving a customer inquiry) with an acceptable success rate.
Identify weaknesses: Surface hidden failure modes, such as an AI agent that handles customer FAQs well, but fails in nuanced cases.
Enable iteration: Reliable metrics enable organizations to measure improvements after design or model changes in accuracy, latency, cost, or user experience, without relying on guesswork.
Compare approaches: With new AI frameworks and models emerging constantly, consistent evaluation provides a fair way to benchmark and choose the best option for a specific task.
Manage costs and resources: Measuring efficiency metrics like compute costs, time, and API usage helps with cost control. For instance, you might find that two agents might have similar accuracy, but one costs more to run at scale.
Ensure trust and safety: Robust evaluation practices are key to turning agentic AI pilots into reliable, production-ready systems that deliver lasting value.
By systematically evaluating AI agents across their lifecycle, organizations can ensure an AI agent is both doing the right things (effectiveness) and doing them well (efficiency and reliability). This enables teams to optimize AI agents, advance their AI capabilities, and minimize the risk associated with unsafe, unreliable, or biased agentic AI.

2 major pitfalls to dodge when converting to AI customer service
How does AI agent evaluation work?
Evaluating an AI agent requires a structured approach within a broader formal AI agent framework that combines process observability with output validation. Evaluation methods vary, but typically include the following steps:
1. Define goals and success metrics
The first step is to establish what “success” looks like for your AI agent. Each of the functions, skills, or execution branches of the agent should be evaluated based on its purpose, real-world scenario, and desired outcomes.
For customer support agents, this would involve metrics like first-contact resolution (FCR), response accuracy, and CSAT scores. You can get as granular as you like with your AI agent testing and evaluation. For instance, you might evaluate the retrieval step of a RAG skill when retrieving customer data from a CRM.
In the next section below, we’ve outlined many of the key metrics for AI agent evaluation.
2. Collect data for a thorough test suite
To be effective, AI agent evaluation requires test sets that are representative of the real-world scenarios it might encounter. These datasets should include both typical interactions and edge cases that push the agent’s limits. These serve as your “ground truth,” a baseline to measure performance against.
You don’t need thousands of examples—focus on coverage over quantity. For example, if you’re building an AI agent for customer service, you might assemble datasets from customer inquiries and chat logs to create test cases for:
Routine inquiries like “Where’s my order?”
Complex multi-step workflows like updating a subscription with exceptions
Edge cases like off-topic or ambiguously phrased requests
Stress tests for high volumes of inquiries in peak periods
By preparing a comprehensive range of test cases that reflect the gamut of possible scenarios, you can evaluate not just whether the agent gets the “right” answer, but how consistently it performs across varied conditions. Over time, you can expand or modify this set as new usage patterns and behaviors emerge.
3. Outline the AI agent’s workflow
Next, you’ll break down every potential step in an agent’s workflow. By mapping each step in the agent’s logic—whether it’s calling an API, making a decision, or generating a response to a customer—you can evaluate each step individually and more easily pinpoint issues.
4. Pick the right evaluation methods
Once you’ve mapped out the steps in your agent’s decision path, you can decide how best to evaluate each of them. There are two main strategies:
Compare to expected outcomes: If you can specify the result you want in advance—say, a particular answer or piece of data—you can measure the agent’s output against this known value. This rule-based approach shows where outputs are off and delivers the best results for reproducibility when trust and safety are in question.
LLM-as-a-judge or manual review: If there’s no definitive “correct” output, or you want qualitative feedback (like how natural an answer sounds), you can involve another language model or a human reviewer. This semantic approach to evaluation provides nuanced insights into qualitative factors like tone or user experience.
AI agent evaluations often combine these strategies, as the end goal is to gather reliable data that guides improvements. For example, you might use automated tests to source metrics about response accuracy and efficiency, and use human reviewers for qualitative feedback on the user experience. There’s a strong emphasis on reproducibility in evaluations, so testing can be automated and scaled so long as the results remain comparable and trustworthy.

8 major support hassles solved with AI agents
5. Conduct testing
AI agents need to be evaluated across varied environments with test sets that reflect every possible path the agent might take. For example, if you’re building an AI agent for omnichannel AI customer service, the test scenarios should span all supported interactions, as well as unsupported requests that the agent must escalate appropriately.
Beyond validating individual steps, it’s equally important to assess how the agent operates across the entire workflow. This means reviewing whether the agent:
- Chooses the right function or tool for each step.
- Passes along the correct parameters and context.
- Executes workflows efficiently, avoiding loops or redundant actions.
- Delivers coherent, context-aware outcomes that align with customer expectations
6. Analyze results and benchmark
Finally, it’s time to analyze how well your AI agent performed. Beyond evaluating if the outcome was correct, assess whether the agent’s logic path was efficient, reliable, and scalable. Ask questions such as:
Did the agent pick the right tool for the job?
Did it call the correct function and pass along the right parameters?
Was information handled in the right context?
Did the agent produce a factually correct and useful response?
Benchmarking AI agent performance is important, since new AI agent frameworks and AI models continue to emerge (LangChain, AutoGen, OpenAI SDKs). By running the same test tasks across different models or agent setups, organizations can compare performance along key dimensions even as new processes and technologies emerge.
7. Optimize, iterate, and monitor in production
Now you can start to refine your AI prompts, streamline agent logic, or reconfigure agentic architectures to improve agent performance at scale, minimize risk, and optimize system efficiency for AI scalability and resource usage.
For example, use cases for customer service AI agents can be improved by:
Accelerating response generation and task completion times.
Spotting variations in error or AI hallucination rates in specific contexts.
Identifying when and why handoffs to human agents happen too often.
Evaluation doesn’t stop at launch, as it's impossible to anticipate every query your agent will encounter in the real world, or all the possible outputs of an LLM. That’s why ongoing observability is critical. By feeding production data back into your development cycle, you can retrain, fine-tune, and adapt your agents as part of a truly robust system.
To help with this, the leading AI agent builders like Sendbird provide analytics dashboards and observability features like real-time AI agent monitoring. This enables teams to detect and address performance issues in the moment, while tracking KPIs like resolution time, CSAT, cost per interaction, and tool usage to inform regular evaluations.

Boost CSAT with proactive AI customer service
AI agent evaluation metrics
Organizations must be able to determine if agents are performing as intended. The following AI agent metrics can help to quantify the various dimensions of agent performance:
Task-specific and functional quality
Success rate/task completion: % of tasks completed correctly.
Error rate: % of failed or incorrect outputs.
Latency: Time taken to process and return results for an individual step or entire task.
Cost efficiency: Resources used per action (tokens, compute time, API costs).
- Output quality:
LLM-as-a-judge: Evaluates output quality through semantics when no ground truth exists.
BLEU / ROUGE: Compare AI-generated text against human-provided references.
Responsible and ethical AI
Bias and fairness score: Detects disparities in outputs across user groups.
Policy adherence rate: % of responses aligned with internal compliance and policy rules.
Prompt injection resilience: Measures success rate against adversarial prompts.
User Interaction and customer experience (CX)
CSAT (Customer Satisfaction Score): User-rated quality of responses.
Engagement rate: How often users interact with the agent.
Conversational coherence: Ability to maintain contextually relevant dialogue.
Task completion (UX): % of user tasks completed successfully.
Function calling and workflow reliability
Correct function selection: Whether the agent chose the right function.
Parameter accuracy: Correctness and completeness of inputs passed in an initiated function.
Execution path validity: Avoiding unnecessary loops or repeated calls.
Semantic grounding: Ensures parameter values derive from valid sources (user text, context, API defaults).
Unit transformation accuracy: Proper handling of format/unit conversions (e.g., currencies, dates).
AI agent evaluation example
Say you’re an online retailer that wants to build an AI agent to handle the common use case of “Where’s my order?” (WISMO) queries. Before we outline how to evaluate this process, what actually happens within the agent?
1. The agent has to determine which tool or API it should call based on the user’s query. It needs to understand the customer’s intent—whether they’re asking about an existing order, a return, or something else.
2. Next, the agent might call the API for the order management system (OMS) to retrieve the shipping status, then cross-check with the logistics provider for real-time tracking updates. Along the way, it might ask questions to confirm the order number or delivery address.
3. Finally, the customer expects a friendly, accurate response that includes the current delivery status and, if effective, resolves the issue without escalation.
To evaluate this agentic AI workflow step by step, you would want to ask key questions like:
Did the agent select the right system to query (OMS vs. returns database)?
When it formed the API call, did it use the correct function and pass the right order details?
Did it apply the customer’s context correctly, such as the order date or shipping method?
Was each response correct, brand-aligned, and satisfying to the user?
Plenty can go wrong without evaluation. For instance, the agent might confuse two orders with similar IDs or fail to include real-time tracking data, leading to an incomplete answer. Worse, it might pass the wrong parameters to the logistics API, showing “delivered” when the package is still in transit.
This is why effective evaluation goes beyond just checking the final message. You need to trace how the agent makes decisions at each step: the tools it chooses, the way it interprets context, and the logic behind its reasoning.

How to choose an AI agent platform that works
AI agent evaluation best practices
Measuring the right metrics is key to successful evaluation, but how you implement AI agents is equally important. To ensure your agents perform reliably and continuously improve, keep these best practices in mind:
Balance multiple metrics
Rather than optimizing for a single KPI, a comprehensive evaluation must consider accuracy, latency, cost, CSAT, and safety together. AI agent dashboards show these metrics side-by-side so teams can evaluate tradeoffs effectively and efficiently.
Benchmark and compare
Monitor and measure your LLM agents' performance across different regions, use cases, and versions against baselines to identify regressions and evaluate ROI—whether that’s human benchmarks, legacy automation, or previous agent versions.
Automate evaluation when possible
Bake testing into your CI/CD or MLOps pipeline. With continuous evaluation, regressions can be caught before they reach production, saving both cost and customer frustration.
Keep logs for visibility
Detailed AI agent activity logs—down to function calls, reasoning chains, and handoff decisions—are vital for debugging and retraining, providing transparency so teams can trace decisions back to their data sources.
Incorporate human feedback
User feedback loops are crucial for optimizing customer-facing agents. CSAT surveys, in-line feedback, and conversation reviews provide qualitative signals to complement quantitative metrics.
Stress test for robustness
AI agents should be evaluated not just on happy-path interactions but also on edge cases, adversarial prompts, and high-volume scenarios to ensure they’re resilient under pressure.
Document and version everything
Track not just agent versions but also evaluation setups, test cases, and criteria to maintain accountability and consistency across iterations.
Iterate for continuous improvement
AI agent evaluation isn’t a one-off task. By closing the loop between monitoring and retraining, organizations can steadily improve accuracy, responsiveness, and cost-efficiency.
Use a framework instead of ad hoc tests
Frameworks like CLASSic (Cost, Latency, Accuracy, Security, Stability) or Sendbird’s AI TrusT OS, an agentic AI governance offering framework, offer structured approaches to scaling evaluation processes with clear guardrails and enterprise-grade AI governance and control.
Build lasting customer trust with reliable AI agents
Popular AI agent evaluation tools
AI agents are evolving rapidly, and various tools are emerging to help organizations automate the complex process of testing agents and gathering insights for improvement. Some of these include:
Libraries
Developer-friendly libraries like DeepEval, Ragas, Promptfoo, and HuggingFace Evaluate provide specialized functions for programmatic testing. These AI agent evaluation tools make it easier to benchmark accuracy, analyze outputs, and validate reasoning paths directly within your development workflow.
Open-source platforms
Comprehensive platforms such as LangSmith and Weights & Biases offer end-to-end observability to ensure agent performance. They log interactions, track metrics over time, and provide visualization dashboards—helping teams compare versions, identify regressions, and monitor production behavior at scale.
Cloud-native solutions
Enterprise-focused platforms like Databricks offer integrated pipelines for large-scale agent evaluation. These are well-suited for organizations that need to combine agent performance analysis with broader data engineering, governance, and compliance workflows.
AI agent builders
The best AI agent builders come with a robust suite of AI agent evaluation tools to support key use cases. Sendbird, for instance, offers built-in observability features like Activity Trails that provide real-time transparency into agent logic, tool use, and what data corresponds to each output. This provides both granular visibility and enterprise-grade scalability, supporting evaluation to ensure AI agents meet expectations across CX, compliance, and business goals.
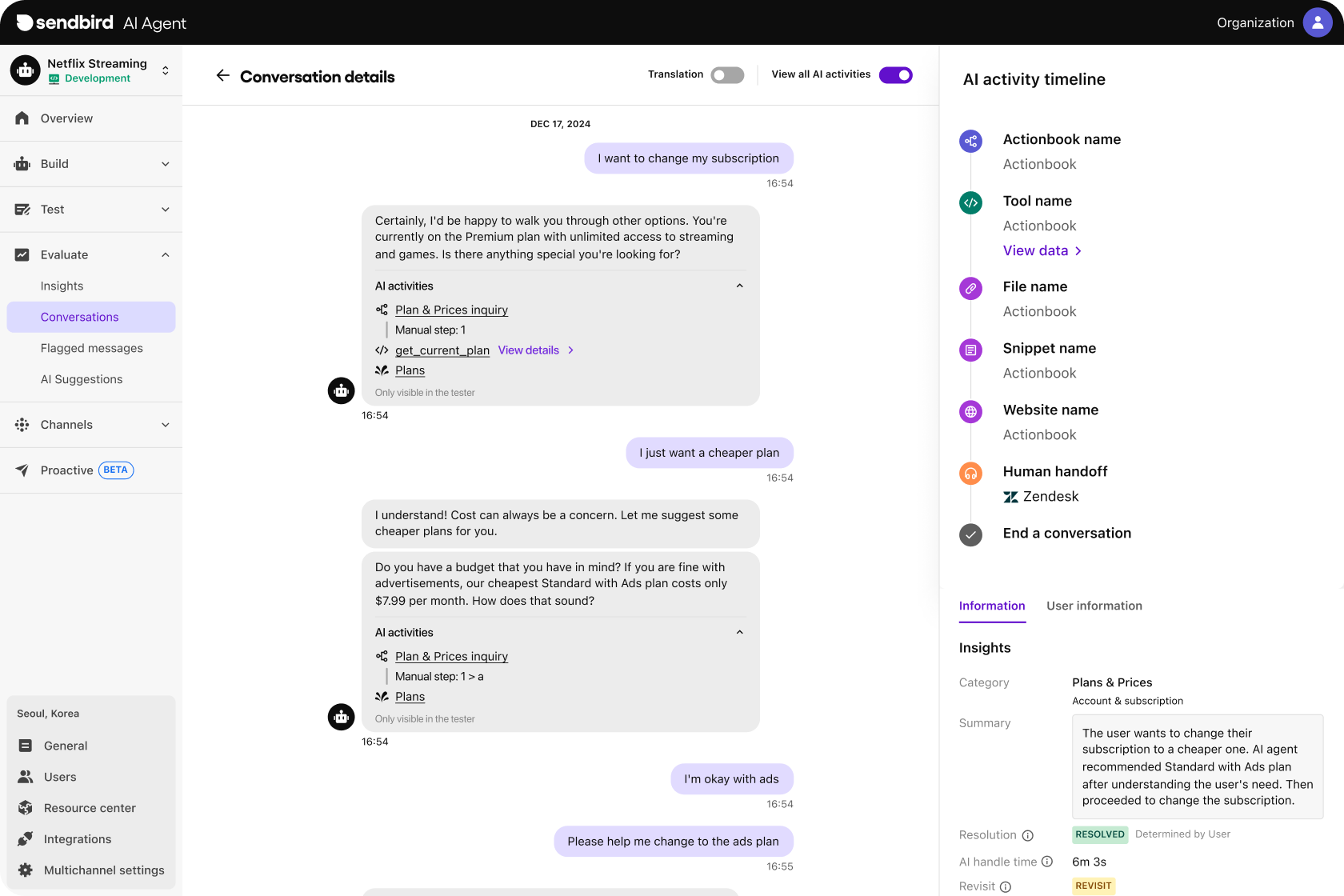
AI agent evaluation with Sendbird
Evaluating your AI agents isn’t just about catching errors before they impact customers—it’s about building trust, ensuring performance, and scaling into real value. With Sendbird’s AI agent platform for customer support and CX, you don’t have to start from scratch.
Our AI Trust OS provides built-in features for observing and evaluating AI agents across their lifecycle. This shows you exactly how your agents reason, which tools they call, and what data they rely on—and how these processes correspond directly to outputs. This gives your teams the ability to monitor workflows step by step, retrain when necessary, and maintain accuracy at scale without guesswork.
To learn more, contact sales or request a demo.









