
7 Optimizations we made when migrating from AWS EC2-ASG to EKS


What is AWS’s Elastic Kubernetes Service (EKS)?
Amazon EKS (Elastic Kubernetes Service) is a managed Kubernetes service provided by AWS. It makes it easy to deploy, manage, and scale containerized applications using Kubernetes on the AWS cloud or on-premises.
Switching Sendbird’s chat service from AWS EC2-ASG to EKS
Sendbird utilizes Amazon EKS across various service infrastructures, but its core workload, the Chat API, has long been operated on an EC2-based Auto Scaling Group (ASG). Over time, the ASG-based infrastructure encountered several limitations, such as:
delays in node provisioning,
lack of flexibility in instance types,
and difficulties in operational automation,
leading to increased burdens in terms of scalability and cost.
Consequently, Sendbird decided to fully transition its primary workloads, including the Chat API, to an Amazon EKS-based system.
We aim to share the strategies adopted, challenges faced, and specific optimization measures implemented to address these issues.

8 major support hassles solved with AI agents
Cluster configuration: Terraform + ArgoCD
Sendbird currently operates approximately 80 EKS clusters across 11 AWS regions worldwide, and the foundation for maintaining and managing them reliably lies in consistent infrastructure configuration and automated cluster setup. In a large-scale environment managing dozens of clusters, automating and systematically organizing the cluster creation and operation process is crucial for both operational stability and development productivity.
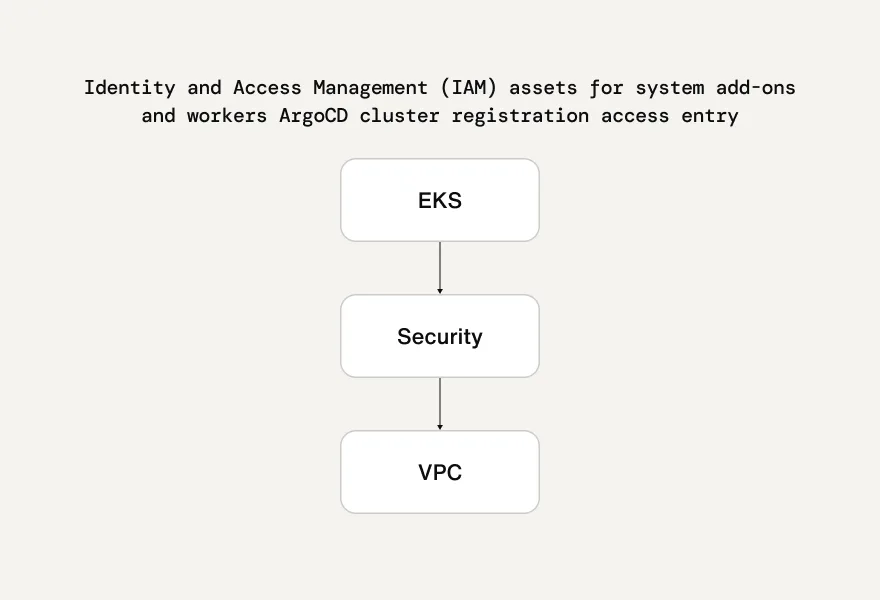
Sendbird defines all cluster resources declaratively using Terraform, organizing its Terraform state by separating components into Virtual Private Clouds (VPCs), security, and EKS. This separation reflects the nature and lifecycle of resource types within a given cluster.
For example, resources with low change frequency, such as networks or security groups, are maintained in separate states, while frequently changing application-related resources are managed separately to minimize conflicts and dependencies. When a cluster is created, it is automatically registered with ArgoCD, which is designed to automatically deploy necessary system applications. This allows the setup process of a new cluster to proceed quickly and predictably.
Network components management: Kube-proxy and aws-cni through Helm charts
Additionally, Sendbird manages key network components like kube-proxy and aws-cni directly through Helm charts instead of using the default method provided by EKS Addon.
The challenge
While EKS Addon is advantageous for quick deployment, achieving detailed control in case of issues is challenging. It does not support flexible configurations at the Helm chart level, making it difficult to meet complex operational requirements.
Sendird’s solution
Therefore, Sendbird directly manages these components as Helm-based applications integrated with ArgoCD, enhancing fault response capability and configuration flexibility.
ArgoCD configuration
The challenge
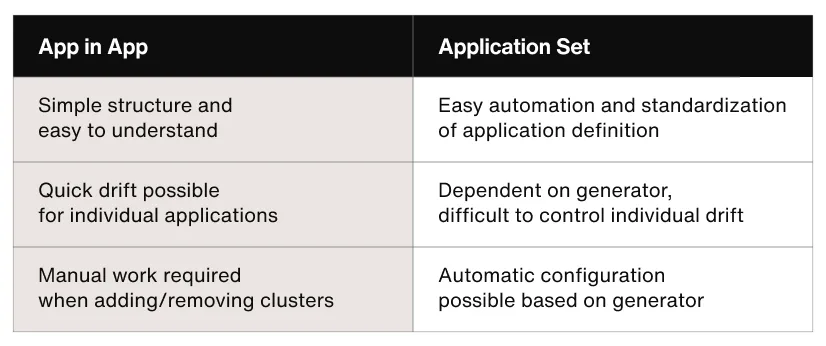
The ArgoCD configuration method has gradually evolved based on operational experience. Initially, the App-in-App pattern was used to configure system applications within the cluster, but there were difficulties managing cluster metadata and achieving consistent automated deployment for new clusters.
Sendbird’s solution
To improve this, Sendbird introduced ApplicationSet, configuring it so that related applications are automatically provisioned when a cluster is created. However, for service workloads, the need for individual configuration or debugging of each application is high, making the App-in-App method still advantageous in many cases, and thus it is used in parallel with ApplicationSet.
App-in-app vs. application ArgoCD configuration
The cluster setup process is an important foundational task that goes beyond simple initial configuration to ensure consistency and control throughout the entire lifecycle. In environments operating multiple regions and clusters, establishing systematically automated infrastructure provisioning and configuration management systems becomes key to operational efficiency and fault response.
Node provisioning: Karpenter + Bottlerocket
Amazon ASG + Cluster Autoscaler limitations
The speed and flexibility with which node resources can be adjusted in Kubernetes are key factors in determining the stability and cost-efficiency of a cluster. The previously used combination of Auto Scaling Group (ASG) + Cluster Autoscaler was sufficiently stable, but the following issues have become increasingly apparent:
The node provisioning speed is slow, causing workload wait times during large-scale scaling situations.
There is a lack of cost optimization potential due to limited instance-type settings.
Fine control makes it challenging to respond to various types of workloads.
Sendbird’s solution
To address these issues, Sendbird introduced Karpenter to completely revamp the node provisioning structure. Karpenter supports maximizing resource utilization by creating nodes in real-time according to workload requirements and dynamically selecting instance types and availability zones.
Karpenter configuration
The Karpenter configuration for Sendbird is designed based on the following strategic considerations:
EC2NodeClass
Ensure fast boot speed: Apply Bottlerocket OS to all nodes to reduce node creation time.
The default instance is Graviton (ARM64): Set as default for cost-effective performance.
x86_64 fallback configuration: Ensuring flexibility in case of difficulties in obtaining Graviton instances
- Appropriate sysctl and kubelet settings
Connection-related settings such as net.core and net.ipv4|ipv6
Kubelet registry QPS and burst settings, etc.
Other OS-level settings
NodePool Segmentation
We achieved operational efficiency and cost optimization by logically separating node pools according to workload characteristics.

Each NodePool is configured to use the latest possible instance types and specifies fallback instance groups to maintain a stable resource supply if a specific type is unavailable. In particular, the stable NodePool sets the consolidation budget to 0, restricting pod rescheduling only when a node is empty. This prevents unnecessary relocation of critical workloads and enables predictable operations.
The results using Karpenter
By introducing Karpenter as above, the node creation speed has become several times faster than before, and the ability to handle peak traffic has dramatically improved. Cost optimization using various instance types has become possible, and workload migration and maintenance without operational downtime have become more flexible. It has become possible to manage more clusters stably with fewer resources, and resource utilization within the cluster has also improved.

Leverage omnichannel AI for customer support
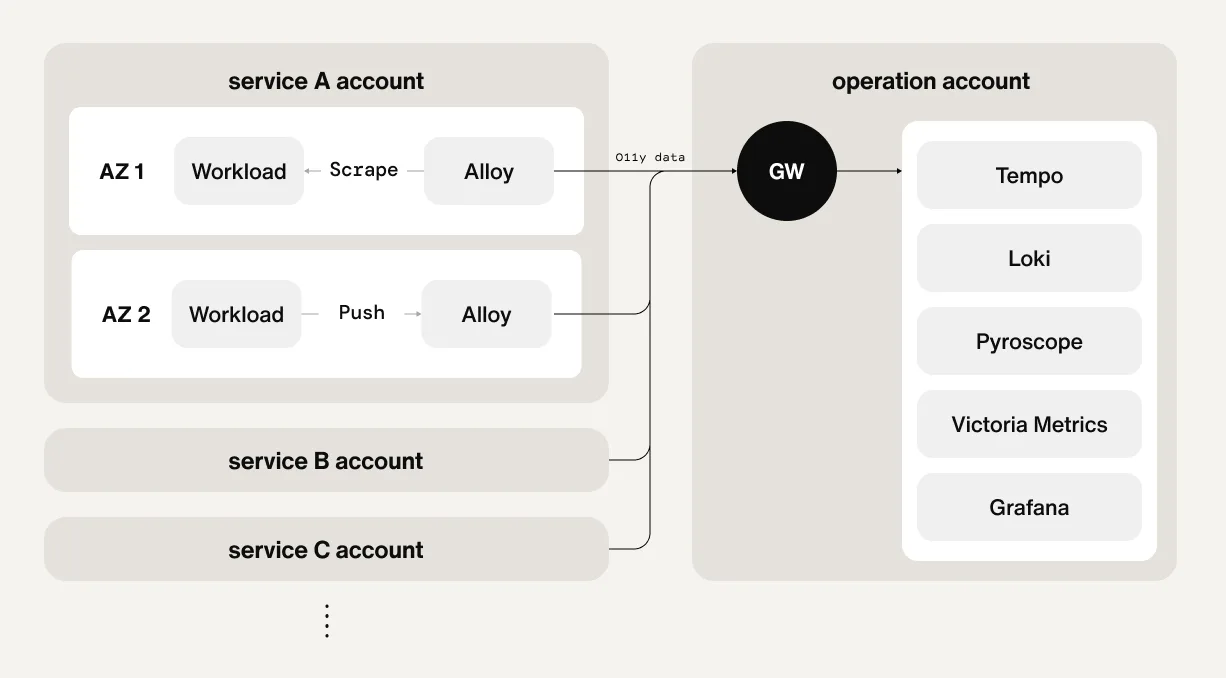
Observability
In a Kubernetes environment, workloads move very dynamically, so it is essential to have a consistent log and metric collection system. Initially, we relied on well-known solutions like Datadog, but due to cost concerns, we built our system centered around open source. Currently, we are using the following tools to collect log and performance data:

To prepare for potential segfaults or abnormal termination (crash) during operation, core dumps are configured to be stored in a separate host volume. This setup provides a foundation for post-mortem analysis of the container's state in case of failure, and it has indeed allowed us to secure meaningful debugging information during the problem-solving process.
System logs at the node level are collected from various log sources, including journald, through Grafana Alloy. In particular, for events related to OOMKill, it is often difficult to obtain sufficient information with container-level metrics alone, so journal logs are very helpful in identifying relevant processes at that time. Additionally, various exporters are used to collecting a variety of events and metrics occurring in workloads and AWS-managed services.
There have been design improvements that consider operational efficiency in the configuration method of the observability agent. Initially, all log and metric collection was intended to be handled based on DaemonSet, but it was difficult to set appropriate resources due to varying resource requirements for each node specification, resulting in excessive overall overhead.
Therefore, currently, only simple scrape tasks are maintained in the form of DaemonSet, and other primary observability data is collected by integrating it into each workload in the form of a sidecar. This method allows for consistent collection quality regardless of node specifications, and since the observability agent moves along with the lifecycle of the observed workload, it is advantageous for debugging and analysis.
In-depth considerations and improvements have been made to the observation system in various aspects, such as cost optimization, data consistency, and query efficiency improvement. This article will briefly introduce the core components, with detailed information to be shared in a separate post later.
Metric collection and logging costs optimization
The CloudWatch cost issue
As you operate larger EKS clusters, the cost of CloudWatch calls gradually becomes noticeably higher. In particular, GetMetricData API calls increase exponentially in frequency and data volume as the number of nodes and types of metrics in the cluster grow, potentially leading to fixed monthly costs of several hundred dollars or more.
Sendbird’s solution: YACE (Yet Another CloudWatch Exporter)
To address this cost issue, Sendbird introduced YACE to periodically cache and reuse CloudWatch metrics in Prometheus.
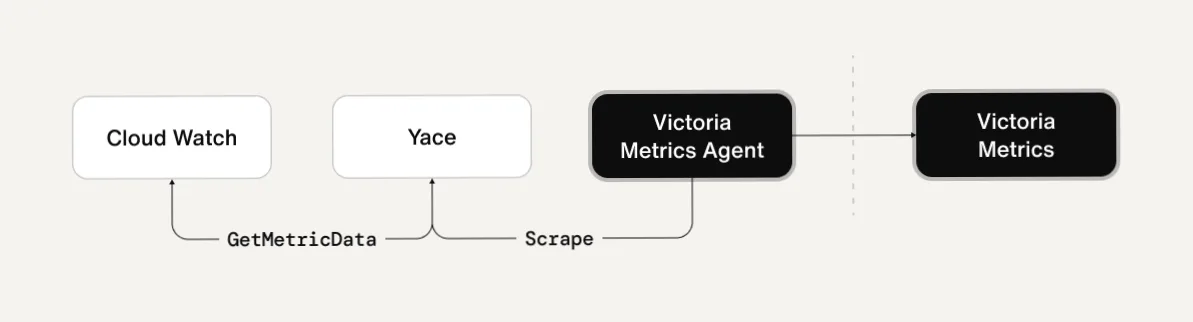
YACE implementation benefits
Initially, there were issues with YACE not accurately reflecting some historical metrics or cost-related metrics being output differently than expected. However, these were gradually resolved through internal patches and assistance from the upstream community. As a result, we were able to significantly reduce the frequency of CloudWatch calls while maintaining observation quality, leading to substantial cost savings by lowering dozens to hundreds of unnecessary API calls each month.
Additional CloudWatch costs
The issue
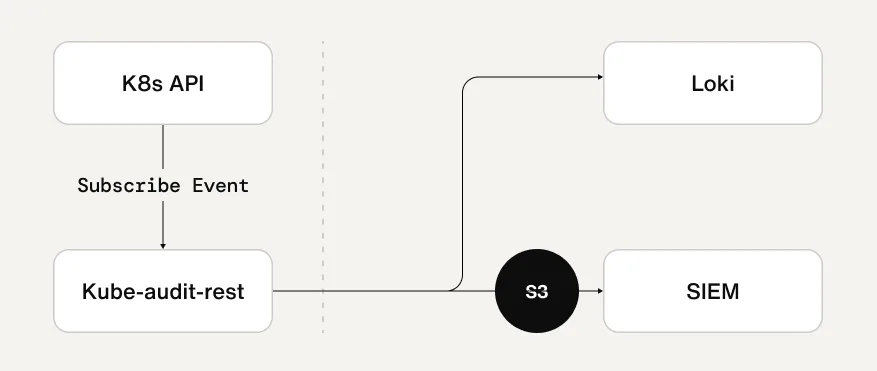
The collection of audit logs also accounts for a significant portion of CloudWatch costs. By default, collecting Kubernetes audit logs results in frequent PutLogEvent calls, and the burden increases, especially when there are many nodes and frequent control plane events.
Sendbird’s solution
To improve this, Sendbird introduced kube-audit-rest to configure audit logs to be sent to Loki and external SIEM platforms instead of CloudWatch. This method is suitable for real-time analysis of log data and security event response, and it was very effective in completely eliminating the log transmission costs of CloudWatch.
In terms of cost visibility, the existing EC2-based tag analysis method had limitations in accurately reflecting container-centric usage. Sendbird is utilizing AWS's Split Cost Allocation Data (SCAD) and OpenCost in parallel to implement cost analysis suitable for a container-based environment.
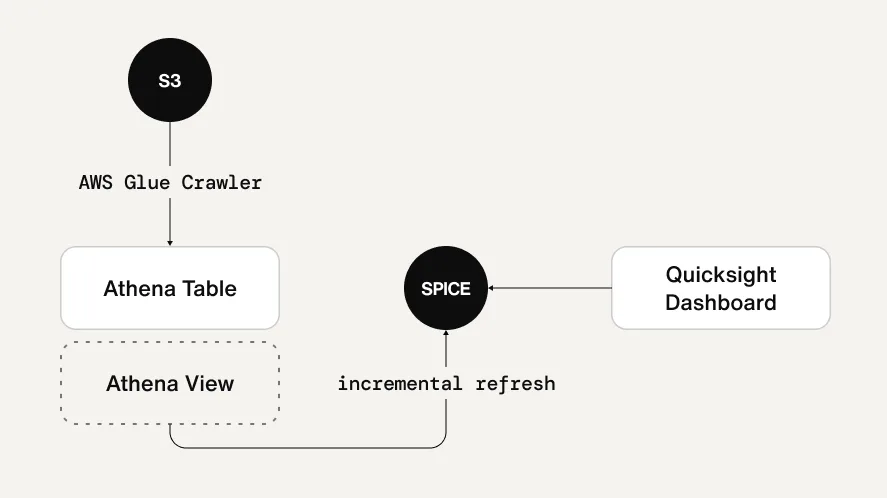
To visualize costs, collect AWS SCAD (Split Cost Allocation Data) through Glue → Athena → visualize with QuickSight.
Athena optimizes query performance and costs through SPICE and daily indexing.
Basically, SCAD distributes node costs based on the pod's resource request ratio, but since the workload's perspective can differ, it considers idle cost alongside OpenCost.
Based on the collected data, we perform periodic resource tuning and bin-packing to maintain cluster efficiency.
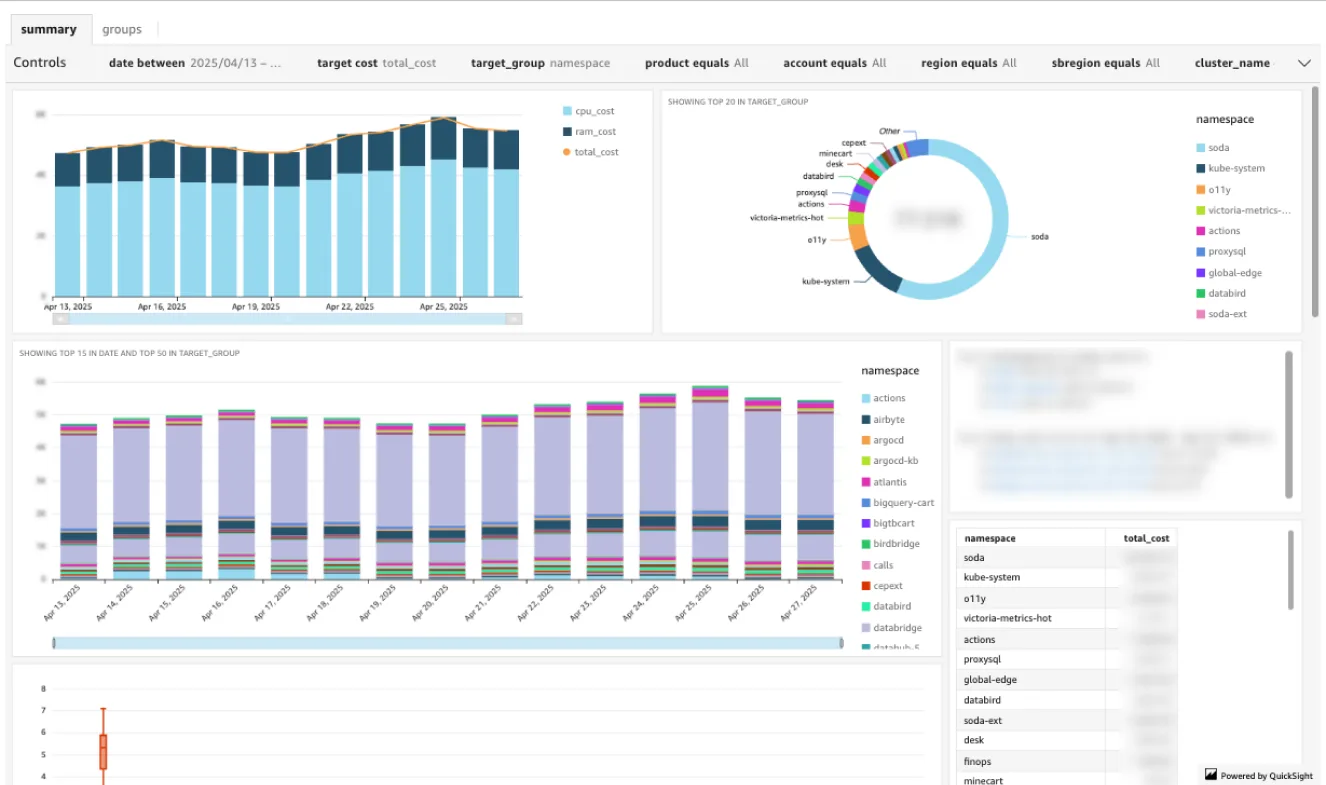
AWS Authentication limitation for cost-sharing
The issue
The cost analysis view created in this way was initially accessible only through AWS authentication, which limited the quick sharing and analysis of cost information within the team.
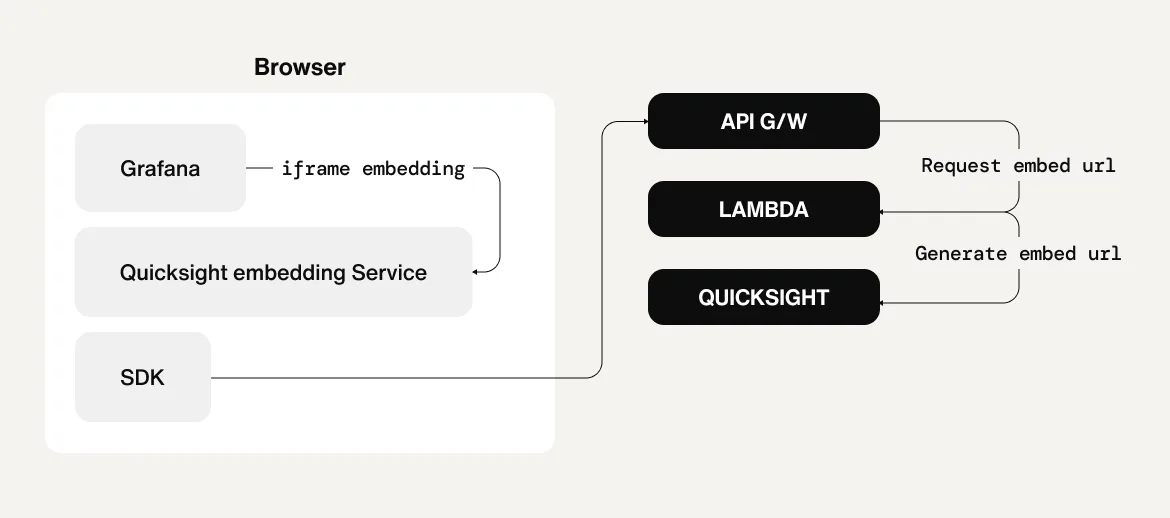
Sendbird’s solution: QuickSight’s anonymous embedding
To address this, we utilized QuickSight's Anonymous Embedding feature to allow access to the dashboard with internal authentication alone. As a result, not only the operations team but also various internal stakeholders, such as the development team and planners, can easily understand the cost structure and gain real-time insights into resource usage.
Container image optimization
The issue
Due to the nature of its service, Sendbird operates workloads across multiple AWS regions and accounts, and container images must be reliably deployed in all these environments. However, transferring images between regions or replicating them across accounts incurs significant costs in AWS, and in the early stages of operation, these cost factors were not sufficiently controlled.
Additionally, there was a need for optimization in terms of deployment speed and image consistency. Issues included long build times, the need to manage images separately for each architecture, and the inefficiency of repeatedly downloading public images across multiple regions unnecessarily.
Sendbird’s container image solution
To address these issues, Sendbird has improved its container image delivery strategy as follows:
Multi-architecture image build (ARM64 + x86_64): It supports both Graviton-based nodes and x86 nodes simultaneously, eliminating image duplication and significantly contributing to reducing operational complexity.
Regional ECR Utilization: We operate independent image repositories for each region to eliminate cross-region traffic and image transfer costs.
Removal of global replication between existing registries: In the past, all images were batch replicated from the origin registry to each region, resulting in unnecessary storage and transmission of unused images, incurring costs.
Introduction of pull-through cache method: Instead of replication, we improved the system by using a cache proxy to fetch images from the original source only when needed and reuse them from the cache thereafter. This method resulted in a transmission cost reduction of over 70%.

Automate customer service with AI agents
Network optimization
As the Kubernetes cluster grows, optimization for IP resources, DNS, egress costs, and cross-AZ/region traffic becomes necessary. First, there was an immediate shortage of IPs in the VPC subnet where EKS is located.
Response to IP shortage issue
Due to a shortage of existing VPC CIDR, we secured IP resources by additionally allocating a secondary CIDR to the cluster. To reduce complexity, we standardized the CIDR structure across all EKS to use the same configuration. We decided to utilize PrivateLink between EKS if issues arise from overlapping CIDRs.
IPAM rate limit issue resolution
The IP was secured, but when Pod creation was frequent, there was an issue where IPs could not be supplied at the necessary time due to the API rate limit. This problem arose fundamentally because there were too many requests, so we changed the approach to allocate Prefix Blocks to Nodes instead of requesting individual IPs.
The cost of traffic going out to the internet was significant, so efforts were made to eliminate it. The issue was particularly prominent in workloads that sync a lot of data externally. By using the IPv6 egress-only gateway provided by AWS, NAT costs can be eliminated, and a method to utilize this was found.
Although nodes were configured as dual-stack and the ENABLE_V6_EGRESS option was enabled in VPC-CNI, there was an issue where the pod prioritized the IPv4 address when the target endpoint was configured as dual-stack. This could be mitigated by modifying settings like gai.conf, but it was still problematic for workloads that do not rely on glibc. Ultimately, for pods requiring IPv6 egress, the approach was to assign hostNetwork and directly use the node's IPv6 address.
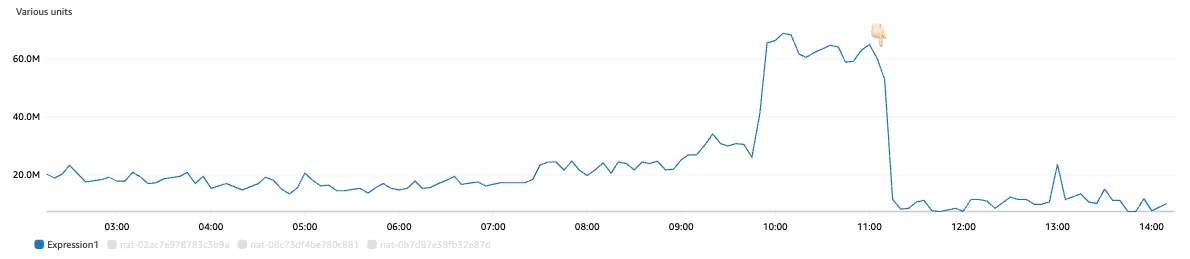
After applying, we were able to achieve significant cost savings in workloads with large data exports.
DNS load mitigation
As the cluster size increases, the amount of DNS queries also increases exponentially, causing overload on CoreDNS and becoming a major reason for reduced responsiveness of the entire cluster. In environments where a large number of pods are frequently created and deleted, DNS response delays can lead to workload start delays.
To address this, Sendbird introduced NodeLocal DNSCache to distribute the load on CoreDNS and improve DNS response speed. However, due to a limitation in the Bottlerocket operating system being used, where multiple DNS servers cannot be registered at the pod level, there remains a structural limitation of a single point of failure (SPOF) in case of NodeLocal DNSCache failure.
Cross-AZ communication cost optimization
In an AWS environment, additional costs are incurred for network traffic between different Availability Zones (AZ), which becomes a significant expense as the cluster grows. Particularly, Kubernetes does not guarantee workload distribution across AZs by default, increasing the likelihood of unnecessary cross-AZ communication. For instance, if Pods of the same service are placed in different AZs and inter-service communication is frequent, the resulting data transfer costs can accumulate and significantly impact the overall infrastructure costs.
Sendbird adopted a strategy of fixing workloads by AZ to ensure that as many workloads as possible communicate within the same AZ, minimizing these costs. This approach also reduced network latency and achieved cost efficiency simultaneously. While Kubernetes' TopologySpreadConstraints can guide workloads to be evenly distributed across AZs at deployment, there is a limitation where these constraints are ignored during scale-in situations.
To address this, Sendbird introduced a per-AZ deployment method that logically divides and operates workloads by AZ, maintaining balanced workload distribution and cost efficiency even during scale-in.
Cross-region communication cost optimization
In AWS's global infrastructure environment, communication between resources located in different regions incurs high network costs. This is particularly true for observability systems like log collection and metric aggregation, where cross-region traffic can become unnecessarily repetitive and lead to significant cost burdens.
Sendbird operates EKS clusters distributed across multiple regions and needs to manage observability data (metrics, logs, traces) generated by each cluster in an integrated manner. Without specific controls, sending data to a central collection point can cause a surge in inter-region traffic.
To prevent this, Sendbird applies an AZ-aware scraping method by default when configuring the observation system, ensuring that components like Prometheus, Tempo, and Loki collect data within the same AZ as much as possible. For the Central Plane, AWS PrivateLink is utilized to ensure both security and cost efficiency during cross-region data transmission. PrivateLink provides a secure network connection between VPCs, allowing communication without a NAT Gateway or Public IP, making it a very effective method for cross-region aggregation and analysis.

Reinvent CX with AI agents
Sendbird's continuous innovation: Responding to Kubernetes limitations
During EKS operations, we are encountering several unresolved Kubernetes issues.
If some containers are in an unready state, metrics for the entire pod are not collected, causing the HPA to not function properly.
Due to the mismatch in req/limit between containers, the QoS class is not guaranteed, making CPU pinning impossible.
During preemption, the PDB is ignored, causing stability issues.
There are no metrics related to ephemeral storage, so when the limit is exceeded, the container status enters unknown.
DaemonSet cannot dynamically adjust resources based on node type.
TopologySpreadConstraints not properly applied during scale-in
In Karpenter, ec2NodeClass cannot be templated.
Chronic segfault in Istio/Envoy's Redis cluster
Sendbird is continuously monitoring these issues and responding through the application of workarounds and community feedback.
Through this EKS transition and optimization, we focused on simultaneously securing scalability, stability, and cost optimization. Each technical choice and structural decision is based on clear objectives and experience-based judgment. Sendbird will continue to conduct technical experiments and improvements to ensure the efficient operation of cloud infrastructure in the future.








