
Sendbird’s risk-aware detection & response program


At Sendbird, we recognize that our customers place their most valuable data in our hands. Maintaining their trust is vital, especially in an era riddled with high-profile third-party breaches. With adversaries continually adapting their tactics, our lean Detection & Response Team (DART) remains ever-vigilant to protect both trust and brand reputation. Maintaining 24/7 monitoring is a formidable challenge, but one we see as necessary to uphold our security commitments.
Our detection & response efforts are focused on the most critical Sendbird processes like CI/CD, identity & access management (IAM), infrastructure operations, SAAS tools, just-in-time sensitive data access, etc. As with any lean team with visibility into multiple log sources, we were quickly dealing with a large number of alerts to investigate & remediate with appropriate actions like network isolation, forced re-authentication, etc.
To address alert fatigue, we either needed a team of analysts who would review the alerts individually or we could scale our program responsibly by automating workflows.
We decided to build a risk-based automation framework to enhance detection, response and containment actions aligned with the severity of alerts. Our goal was to reduce manual effort, accelerate response times, and improve security resilience by making risk the driving factor behind decision-making. In this blog post, we outline our roadmap - from designing risk-based analysis for your org to automating response workflows. We will walk you through our core components, key lessons learned, and our future plans.

Automate customer service with AI agents
Core components
We identified that the automation workflows would need to
correlate suspicious activities related to an entity with their privileges to create risk-based alerting
evaluate the business impact
enact appropriate automated or human-driven remediation
Almost like having our own tireless 24/7 Level 1 analysts.
It is beneficial to clarify how we defined the following terms in Sendbird’s business context before we discuss them in detail.
Risk
Repurposing the NIST definition of risk to fit ours - “A measure of the extent to which Sendbird’s business operations, data or brand reputation are threatened by a security event, and typically a function of: (i) the impacts to Sendbird business operations or our customer data; and (ii) the likelihood of occurrence”.
Risk score
A risk score is assigned based on the severity of impact across a Sendbird entity’s dimensions (mentioned later in the post), in combination with business impact and MITRE ATT&CK kill chain.
With this basis of key terms and partners, let’s jump into the components of the process.
1. Defining the risk
To estimate the risk of a security event, we first defined critical entities and gained near-real-time visibility in their corresponding dimensions. Some critical entities and their dimensions -
Human identities - Identifiers like email or some other unique id, title & department (privileges), geo-location, associated device’s security config
Cloud compute resource - arn, instance profile, security groups associated
When a security event is generated, a risk score is calculated based on
(a) what (if any) dimensions of the entity were unusual;
(b) the inherent access levels of the entity; and
(c) the MITRE ATT&CK tactic associated with the event
The risk score for security events is calculated based on below formula:
risk_score =
dimension_change (dc) # 0 ≤ dc ≤10
+ access_level (al) # 0 ≤ al ≤ 20
+ MITRE_ATT&CK_tactic (mat) # 50 ≤ mat ≤ 100
For efficiency purposes, access-level (al) scores are evaluated continuously and can be queried by the automation workflows at response time. Privilege scores are normally derived based on the title of the user. The score thus reflects the privileged access that users may have by default and also accounts for temporary privileges due to just-in-time access.
At enrichment time, the enrichment workflow correlates the affected user’s most recent Okta Threat Insights and security controls assessment score to finalize dimension_change (dc) scores.
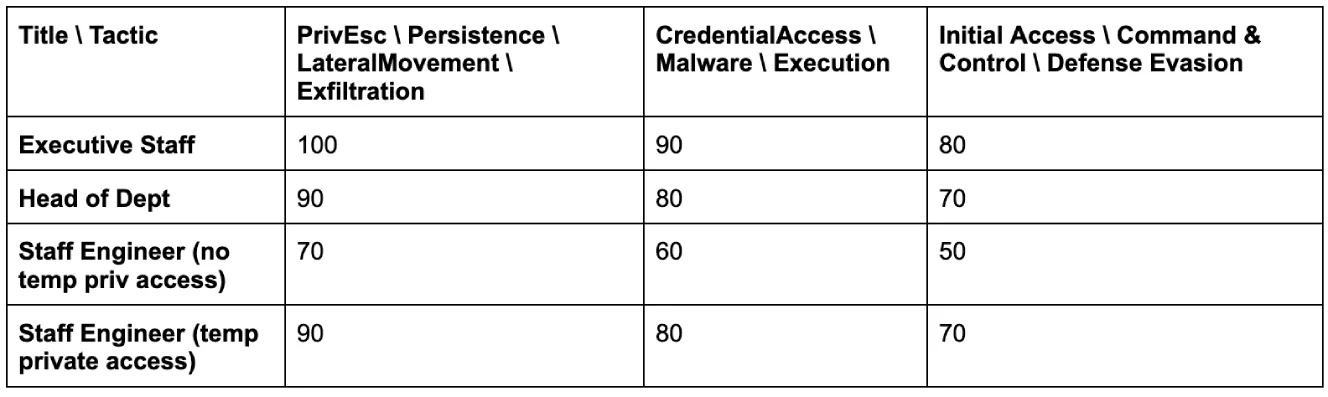
Finally, to tie it all together, we correlate the affected user’s title and MITRE ATT&CK tactics on flagged insights to derive the MITRE_ATT&CK_tactic (mat) scores. Below is a table of our score mapping:
2. Codifying steps to calculate a risk score
Implementing end-to-end automated analysis steps using a SOAR is a tricky task as it differs for each case. Hence we have created smaller, modular plug-n-play “investigative” workflows that surface key insights into the potentially compromised entity and update the risk scores accordingly. Some examples include:
Actions attempted on our production cloud infrastructure,
Critical applications accessed by the flagged entity,
Any other security events and their MITRE ATT&CK tactics associated with the entity
Along with informing the risk score, these findings are continuously updated in Jira to keep a log of the risk score.
For example, a temporarily privileged staff engineer (log source: Okta, info - Title & current Okta Group, default score = 20) logging in from an unusual location (log source: Okta, info - Okta Threat Insights, score = +10) attempting to create a new user in our AWS production infrastructure (log source: Cloudtrail and CSPM, Info - EventName, tactic = persistence, score =+90) would immediately put the risk_score for this entity at 120.
Whenever we add a new log source and onboard its detections, we codify appropriate workflows for risk scoring by applying well-reasoned contextual frameworks that define cross-source events to correlate. We then revisit and refine this contextualization periodically, ensuring that risk scores remain accurate and meaningful over time.
For example, when analyzing domain monitoring system alerts, our workflows incorporate endpoint process logs and automatically raise the risk score if the observed process isn’t from a known subset.
3. Automated remediation to give an illusion of a 24x7 level-1 analyst
Enriched with the above analytical insights and holistic risk score, the automated remediation workflows take action when the risk score exceeds a threshold.
We have codified two types of remediation actions: notification and resolution. Resolution is further boiled down to escalation and auto-resolution. Notably, most events requiring notification-type actions also result in issue auto-closing.
We have tested and rolled out automatic remediation workflows in endpoint and human identity space to limit a Sendbirdian’s Okta access or restrict their network access to Sendbird infrastructure. All of this is done while keeping the system owner in the loop via Slack, updating them on the current status when appropriate.
When events are escalated to on-call engineers, alert contexts like the risk score, holistic risk posture, and entity dimension help determine the next steps.

Harness proactive AI customer support
Workflows in action
To understand these workflows in action, below are example security events and how we respond to these.
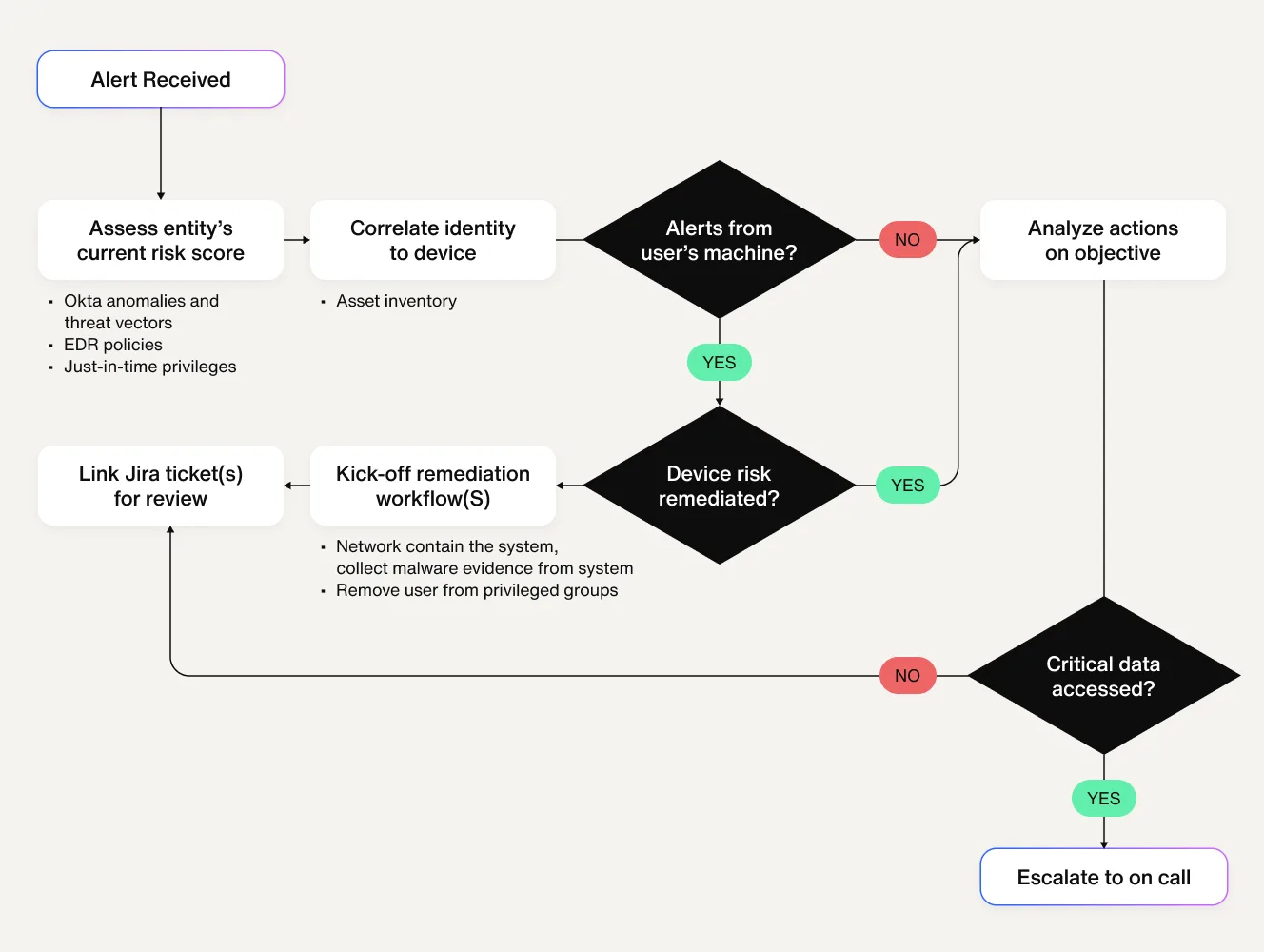
1. Consider an alert for an account generating excessive access-denied events. Once triggered, this event initiates four analysis workflows to assess the severity & risk and three remediation workflows to contain the potential compromise based on the analyses.
(Analysis)
Assess the account’s privileges—If the affected account currently has privileged access (e.g., administrator or elevated system permissions), a risk score increase of 20 is applied.
Evaluate post-trigger activity—If any events occur after the suspicious login attempt (e.g., modifying security settings, accessing sensitive data), the risk score is further increased to reflect the potential damage.
- Assess endpoint compromise risk—Look up the user's machine associated with the suspicious activity and cross-reference Endpoint Detection & Response (EDR) for alerts. If found:
The machine’s risk score is increased accordingly.
The compromised device’s information is passed to the remediation system for further action
Assess risk score with MITRE ATT&CK mapping – Based on the tactic assessment, the identity's overall risk score is updated and passed to automated remediation workflows.
(Remediation)
Limit account access – The affected user’s account is immediately downgraded to minimal privileges. Notify the affected user over Slack about restrictions on identity. Additionally, an on-call security engineer is notified.
Isolate the compromised machine—The endpoint’s access to corporate resources is restricted while collecting forensic evidence, such as recently downloaded unique executables.
- Update incident tracking and documentation – The Jira ticket is automatically populated with the context, including:
User identity details (affected account and role)
The source IP address of the suspicious login
Security logs correlating the event to previous detections
Machine lock status and forensic evidence timestamps
Collected files and artifacts for deeper investigation
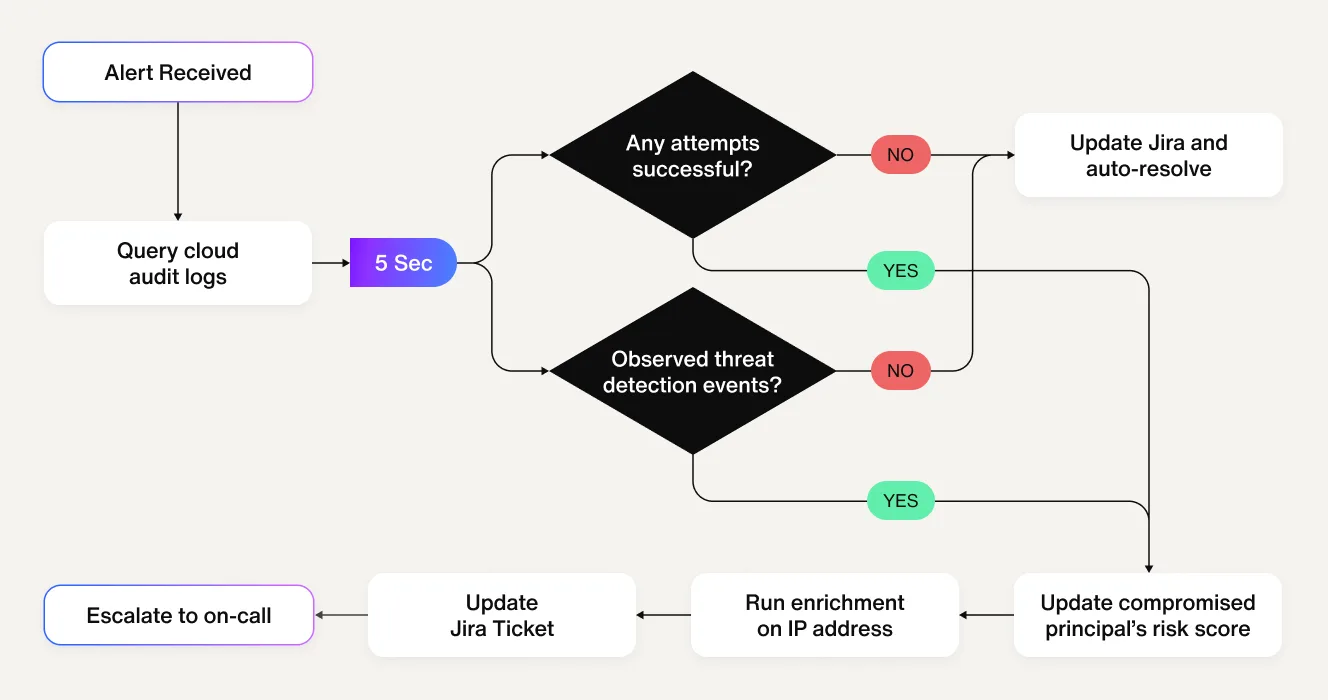
2. For an alert involving external services getting scanned continuously from potentially suspicious IP addresses, the following workflows are triggered:
(Analysis)
Determine if any of the events were successful. CDR findings need context, like why the IP address is malicious and whether any requests from that IP address went through. Relevant evidence is also attached to the Jira issue.
Correlate other critical findings for the targeted resource. Correlate other findings that have triggered the targeted resource.
(Remediation)
Auto resolution - If all attempts failed, provide evidence that all attempts failed, auto resolve the events as benign scanning activity.
- Escalation to on-call - If any of the attempts were successful or other threats were detected along with the intrusion attempts,
Enrich Jira ticket with evidence of events,
Escalate to on-call engineer
Results
We have developed and iterated over this system for the last ~9 months now and have seen significant improvements in our remediation times.
With increased visibility, we could identify and prioritize our most critical alerts even when we were flooded, manage resource allocation with ease, and drive our IR effectively. The alerts are enriched with the least latency, bubbling up the ones with the highest risk priority to on-call engineers.
Our risk formula has been refined since its introduction to production, allowing us to capture critical threats more accurately and realize immediate benefits. For example, unusual activity on a user's laptop was flagged by a custom detection, which triggered a workflow to force re-authentication and minimize exposure.
Similarly, external service scan findings are either auto-remediated or escalated to on-call engineers with detailed evidence—including the targeted cloud resource, the security posture of the cloud resource, and any sensitive data that the resource may have access to. The team can rapidly prioritize threats, reduce the window of vulnerability, and maintain a holistic approach to risk remediation by providing relevant evidence and real-time insights.
And yet, we have automated “almost” everything. While manual investigations remain in place, once the issues are enriched with the risk context, it drastically shortens the decision-making and remediation process for engineers based on their priceless understanding of the business processes. Our goal is to make these insights a part of the detection logic where possible so we can “shift left” the detection logic.

Leverage omnichannel AI for customer support
Lessons learned
Analysis runbooks are HARD but essential for success
Out-of-the-box SOAR action libraries are heavily focused on remediation actions i.e. active changes to user or application attributes. To achieve the same extensibility toward the analysis steps we had to spend significant efforts on baselining user activities so we call out the right findings and suppress the rest.
We also created a knowledge base of investigative queries that engineers can frequently use, as part of the manual analysis. Later, we refined these queries to provide machine-readable insights that can be parsed & accounted for during risk calculation.
Securing the Automation Platform is a Non-Negotiable
When we first deployed our risk-based automation framework, we focused heavily on detection logic and response speed. However, we quickly realized that our automation platform itself was a high-value target. Attackers could potentially abuse overly permissive privileges or tamper with automated actions, leading to widespread security gaps.
To mitigate this, we implemented the least privilege access, strict execution controls, and continuous monitoring on the automation platform. As a result, we hardened our automation layer and ensured that it wouldn’t become an attack vector itself.
Future plans
Extend remediation to cloud resources
We plan to work closely with our infrastructure team to extend the scope of cloud resource auto-remediation workflows. We intend to do this by gathering feedback on the context and evidence of potential intrusion we provide to our on-call engineers. These automated workflows will also be made available in Slack to the right participants for the incident's timeframe.
Using GenAI to build a tribal knowledge buddy
The quickest and easiest win we see with the use of GenAI is the search-and-understand use cases. A quick brief of a couple of examples below:
A summary of the retroactive verdict of the alert—AI can help summarize the analysis of past incidents, providing a clear distinction between past alerts and current ones.
Infer context from Wiki pages and Jira tickets—Similarly, Jira and Wiki provide much of the context for projects. We intend to use GenAI offerings from Atlassian to get summaries of project purpose, timelines, key collaborators, and systems components.
References
Our framework owes a debt to the community: a number of excellent blog posts shaped how we designed, deployed, and operationalized risk‑based evaluation. A couple of key references include:
1. An informative blog post by Netflix’s Cloud Infrastructure Security team
2. A video from Wild West Hackin' Fest, an information security conference: "Magnets for Needles in Haystacks: Using MITRE ATT&CK w/ Risk-Based Alert"









