
What is deep learning?
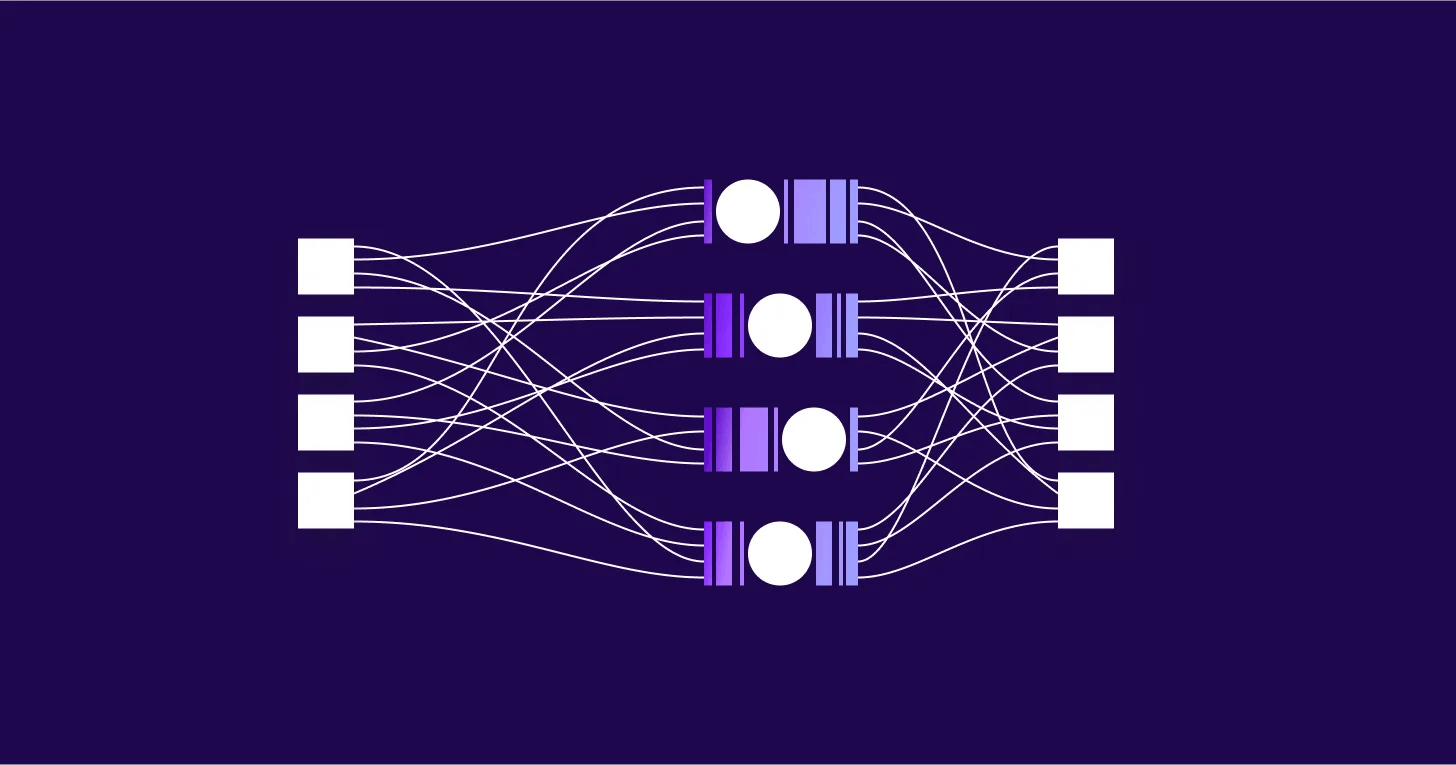

Deep learning is a subset of machine learning that uses layered neural networks to analyze and learn from data in a way that mimics the human brain. These networks often comprise dozens or even thousands of neuron layers, allowing systems to detect patterns, extract meaning, and make decisions with minimal human input.
What sets deep learning apart is its ability to handle vast amounts of unstructured data, like text, images, audio, or video, and turn it into useful predictions or classifications. Unlike traditional machine learning, which often relies on manual feature extraction and structured datasets, deep learning models learn directly from raw inputs. They also support different training approaches, including supervised and unsupervised learning.
With unsupervised learning, deep learning models can identify patterns, features, and relationships on their own, without the need for labeled data. Over time, they refine their understanding through exposure to more data, enabling continuous performance improvements.
"Deep learning has revolutionized the field of artificial intelligence, enabling machines to recognize patterns and make decisions with unprecedented accuracy."
– Geoffrey Hinton, Computer Scientist and Nobel Laureate in Physics
Modern deep learning architectures, such as transformers, power many of today’s most advanced AI systems—including large language models (LLMs), generative tools, AI assistants, AI agents, or autonomous vehicles. These models excel at complex tasks like language understanding, machine translation, image and video generation, speech recognition, and recommendation systems. They’re also behind breakthroughs in protein structure prediction, medical imaging, fraud detection, robotics, and predictive maintenance—enabling innovation across healthcare, finance, retail, logistics, and customer service.
What are valuable resources to quickly understand deep learning?
For a succinct overview of how deep learning works and its applications, check this Eye on Tech video.
For a more in-depth mathematical understanding of deep learning, check out this incredible and insightful video, which has over 7M views from the Three Blue One Brown channel.
For a thorough study of deep learning, read this free ebook from Michael Neilson.

8 major support hassles solved with AI agents
How does deep learning work?
Deep learning enables computers to learn directly from raw data—just like humans do through experience. Instead of following fixed rules, a deep learning model makes an initial guess, measures how far off it was, and then improves itself by adjusting internal parameters. This process happens over and over again across vast datasets until the model becomes highly accurate at tasks like recognizing images, understanding language, or predicting outcomes.
At its core, it uses artificial neural networks—layered interconnected nodes (or “neurons”) activated by mathematical functions that apply weights and biases to guide the network toward a correct output (or the “answer”). This is the forward propagation. These networks learn by identifying patterns and refining predictions through backpropagation and optimization to eventually generalize their approach to finding an answer to handle new, unseen data well. The more data they see and the more iterations they run, the smarter they get.
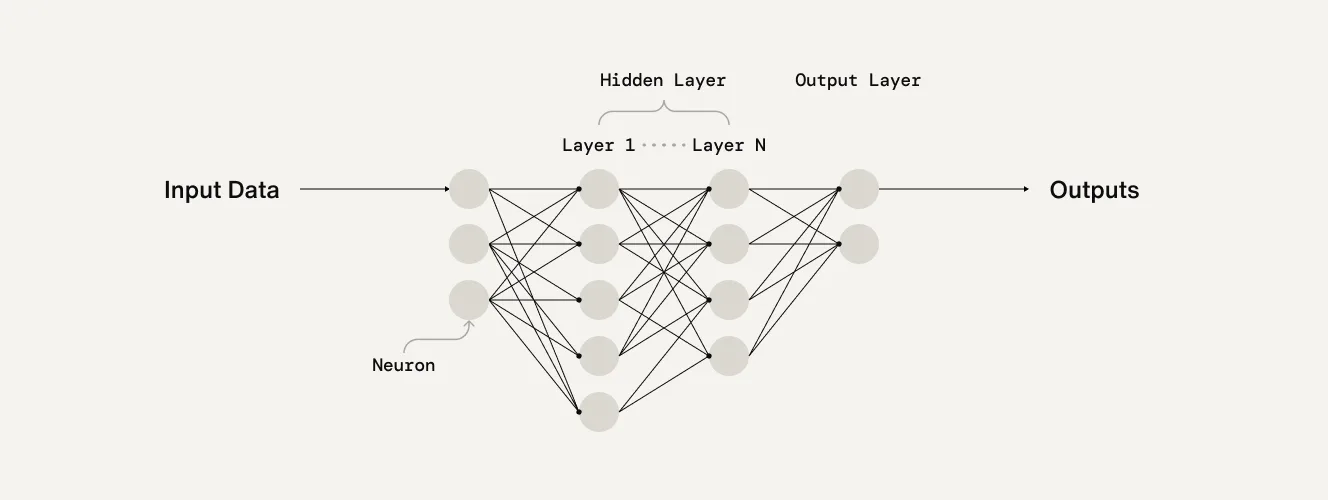
A typical deep learning model is made up of three main types of layers.
The input layer is where data enters the network, such as a message, image, or audio snippet.
Multiple hidden layers, where features—like edges or texture for an image—are extracted and transformed.
The output layer produces the final prediction, classification, or even new content.
The input and output layers are referred to as the visible layers.
What makes these networks “deep” is the number of hidden layers, often dozens or even thousands. Each layer builds on the one before it to learn increasingly abstract representations. In a language model, for example, early layers might identify individual words or phrases, while later layers start to pick up on sentiment, tone, or intent.
What is forward propagation?
Forward propagation is the process in deep learning where neurons in each layer of a neural network are activated using the outputs (or activations) from the previous layer, combined with weights and biases. These values are passed through an activation function to produce the output for the next layer, ultimately resulting in the model’s prediction. The model makes a prediction based on the current configuration of its weights (which determine the strength of each connection) and biases (which help shift outputs for better flexibility).
What is backpropagation?
Backpropagation (short for backward propagation of errors) is the core algorithm used to train neural networks. It is the process of updating a neural network's internal parameters (weights and biases) by propagating the prediction error backward through the network. After comparing the model’s output to the correct answer using a loss function, the algorithm calculates how much each weight contributed to the error. It then uses gradient descent to adjust the weights and biases in the direction that minimizes this error. With each iteration, the model learns from its mistakes and improves its accuracy.
Once a deep learning model is trained, it can apply what it has learned to new data. This allows it to classify images, generate responses, detect anomalies, or support a wide range of intelligent features in real-world applications.
How does deep learning run?
Deep learning thrives on raw computational horsepower. Training large-scale neural networks demands billions of operations across massive datasets, making specialized hardware essential. Graphical Processing Units (GPUs)—designed for parallel processing—excel at this workload thanks to their thousands of cores and high memory bandwidth. When scaling beyond a single machine, cloud-based distributed computing offers the elasticity and speed required for model training at scale without the burden of maintaining costly on-premise infrastructure.
On the software side, modern deep learning development typically relies on frameworks like TensorFlow, PyTorch, or JAX, which provide optimized libraries for tensor operations, automatic differentiation, and model deployment.
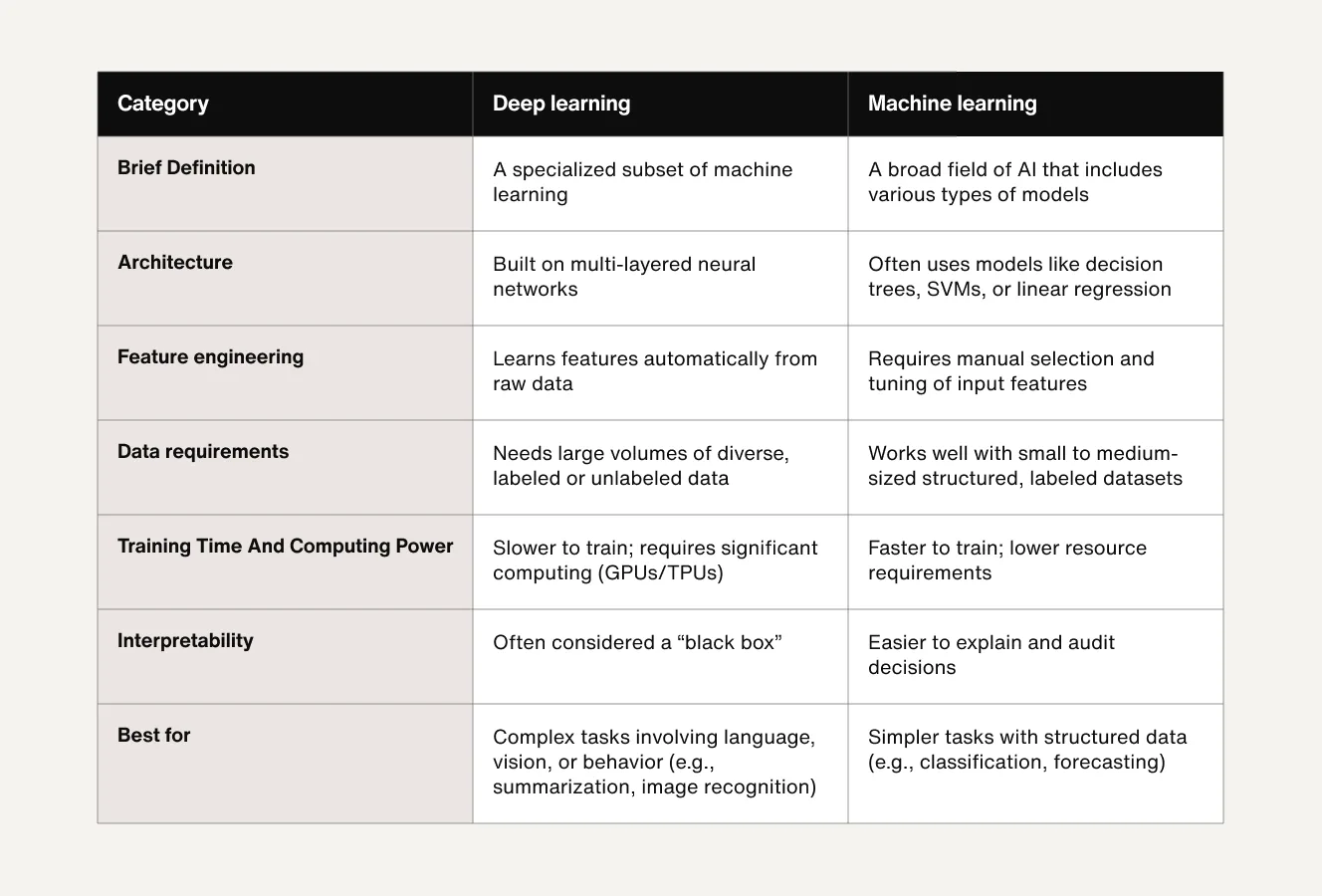
Deep learning vs. machine learning: What’s the difference?
Machine learning and deep learning are closely related. Both enable computers to learn from data but differ in how they process that data, how much human intervention they require, and the types of problems they’re designed to solve.
Machine learning is a broader category that includes traditional algorithms like decision trees, support vector machines (SVMs), and logistic regression. These models typically rely on structured data and require manual feature engineering, meaning humans must decide which variables the model should consider.
Deep learning, on the other hand, is a more advanced subset of machine learning that uses neural networks with multiple layers. These models can learn directly from raw, unstructured data like text, images, or audio, and automatically extract the most relevant features.

Reinvent CX with AI agents
Types of deep learning models
There are many deep learning algorithms and neural networks to choose from based on the problem at hand. Whether you’re generating text for AI concierges, classifying images, recognizing speech, or analyzing numerical data, choosing the right learning model matters.
Here’s a breakdown of nine widely used deep learning models and what they do best.
Convolutional neural networks (CNNs)
What are CNNs?
CNNs or ConvNets are a type of neural network designed to process spatially structured data, such as images and videos. It is primarily used for computer vision and image classification. In a Convolutional Neural Network (CNN), the architecture typically consists of three fundamental types of layers—convolutional layers, pooling layers, and fully connected (FC) layers—each with a specific function in feature extraction and classification.
How does a CNN work?
Convolutional layers extract local features (edges and textures), pooling layers reduce spatial dimensions to retain dominant patterns, and fully connected layers interpret these features to recognize more complex elements and identify the final object.
What are CNNs’ use cases?
CNNs are the foundation of many image-based applications, such as:
Content moderation, flagging inappropriate or unsafe visuals
Facial recognition for identity verification or profile validation
Optical character recognition (OCR) for reading text from documents or receipts
Object detection, such as identifying brand logos, unsafe content, or relevant imagery
Visual search, where users find products or content by uploading a photo
What are the pros and cons of CNNs?
CNNs are efficient at processing large datasets and, therefore, more scalable than image processing. However, they require large labeled datasets for training and can be sensitive to input variations like rotation or lighting. They also have a limited understanding of temporal or sequential patterns, making them less suited for tasks involving time-based data or language. CNNs may also demand significant computational resources for real-time applications, particularly when processing high-resolution or video inputs.
Recurrent neural networks (RNNs)
What are RNNs?
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to process sequential data by maintaining a memory of previous inputs. Unlike traditional feedforward networks, RNNs have loops in their architecture, allowing them to pass information from one step to the next. This makes them particularly well-suited for tasks where the order and context of inputs matter, such as language modeling, speech recognition, time-series forecasting, and real-time translation. You’ve experienced them through applications like Siri, Alexa, or Google Translate.
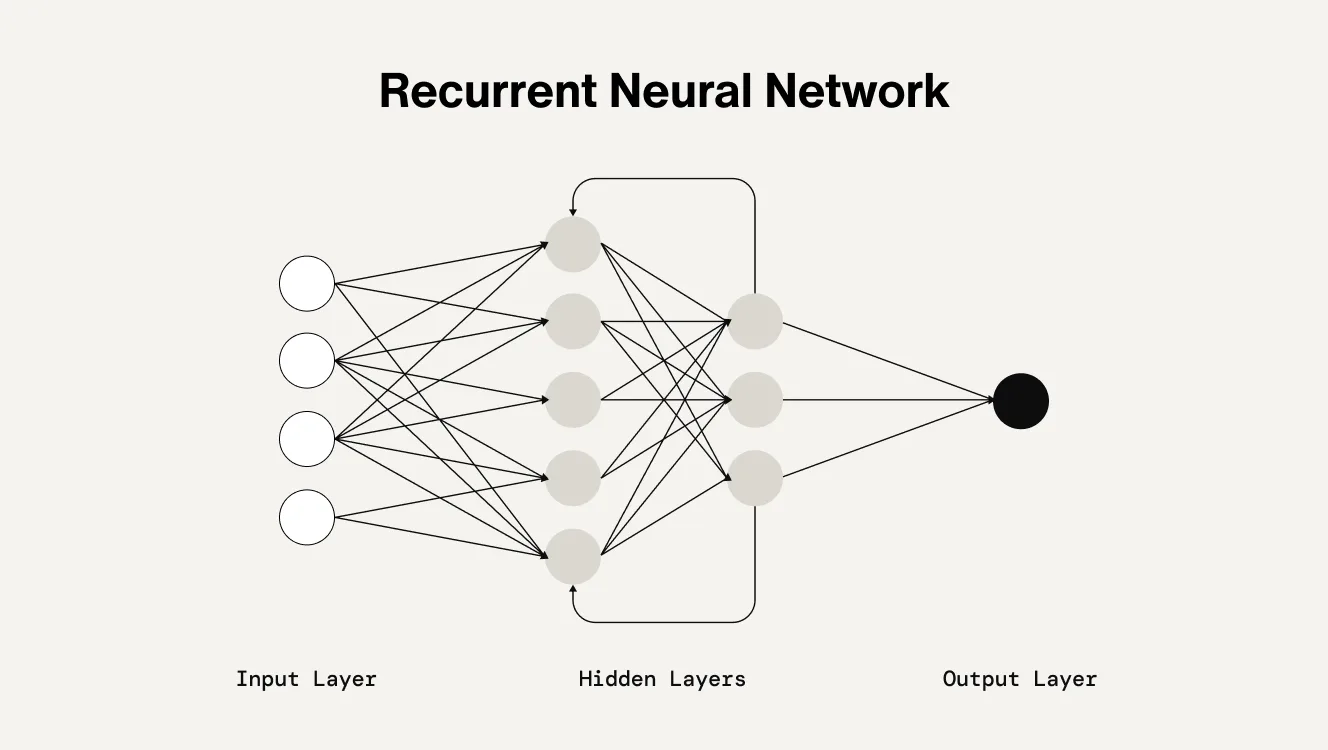
How do RNNs work?
Unlike feedforward networks, RNNs maintain a hidden state that “remembers” previous inputs. It creates a relation between prior input data with current input and future outputs, allowing predictions to be made and weights shared across network layers to be shared. Weights are adjusted through backpropagation and gradient descent to reinforce learning. A specificity about unidirectional RNNs is that they don’t use future data to determine the output. Also, they’re trained using Backpropagation Through Time (BPTT), a variant of backpropagation that unfolds the network across time steps and sums the gradients at each step to update shared weights. RNNs' ability to model temporal dependencies produces flexible input-output patterns like one-to-many, many-to-one, and many-to-many, which are ideal for language, time series, and other context-sensitive tasks.
What are RNNs' use cases?
As a result, RNNs are often used in:
Next-word prediction and autocomplete features in messaging apps
Speech recognition applications that transcribe real-time voice input
Intent classification and sentiment analysis in support conversations
Conversation summarization for extended or multi-turn conversations threads
Chat routing and prioritization based on sequential user signals
What are RNNs' limitations?
Despite being parameter efficient, supporting flexible input-output structures, and their ability to handle sequences by remembering prior inputs to produce more coherent outputs in time-sensitive tasks, RNNs face some limitations, such as:
Long-term dependencies: Traditional RNNs struggle with long-term dependencies. Deep learning algorithms like LSTMs (long short-term memory networks) or GRUs (gated recurrent units) are often preferred for longer sequences, as they can better retain context across many time steps.
Vanishing gradients: The gradient can diminish to a point where all weights converge toward zero, preventing the algorithm from “learning”.
Exploding gradients: Conversely, with too many layers or long sequences, gradients can grow uncontrollably, causing weights to “explode” and destabilize the training.
Computational efficiency: Due to their sequential nature and large number of layers and parameters, RNNs are computationally inefficient and can be slow to train, especially on large datasets.

Leverage omnichannel AI for customer support
Long short-term memory networks (LSTMs)
What are long short-term memory networks LSTMS?
LSTMs are an advanced type of recurrent neural network (RNN) designed to solve one of the traditional RNNs' core limitations: the inability to retain information over long sequences due to vanishing gradients.
How do LSTMs work?
LSTMs overcome vanishing gradient by introducing a memory cell and a set of gates—input, forget, and output—that regulate the flow of information.
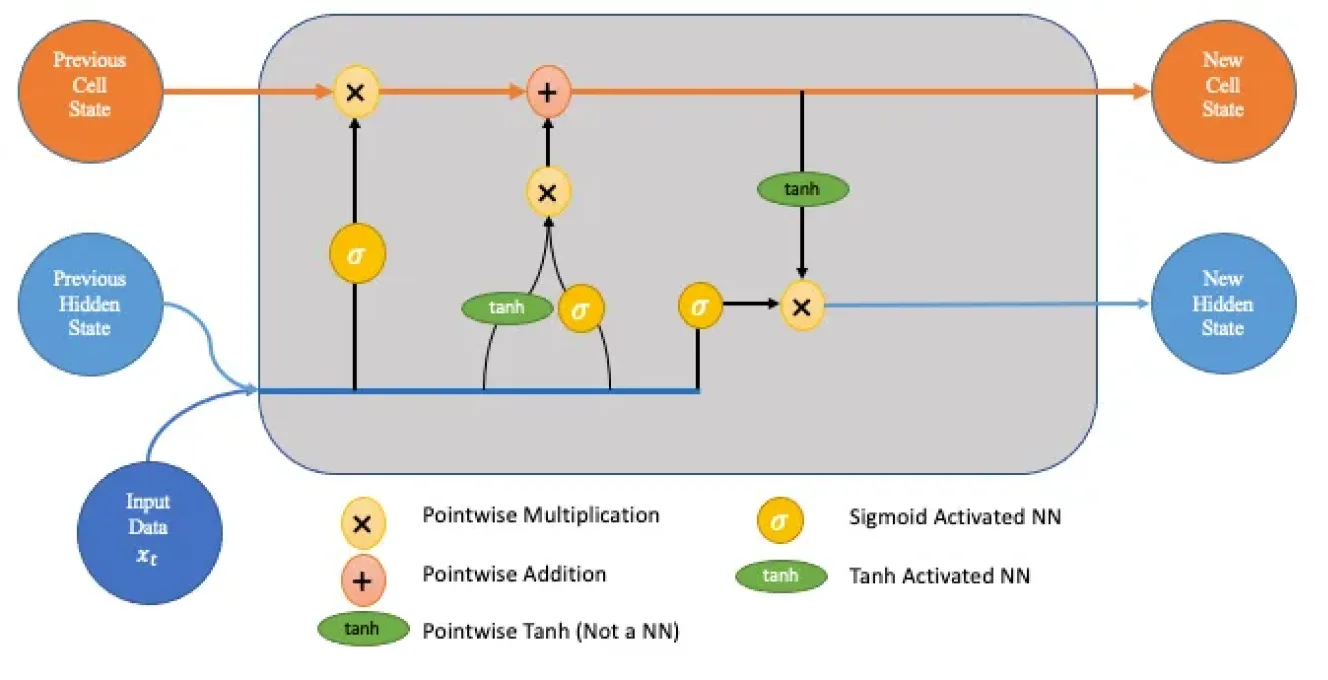
These mechanisms allow LSTMs to decide which information to keep, update, or discard across time steps.
What are LSTMS use cases?
LSTMs' ability to retain information makes them ideal for tasks where context from earlier in a sequence is critical to understanding later elements.
In customer support and messaging products, LSTMs are often used for:
Multi-turn conversation analysis, where earlier parts of a chat influence the appropriate response later on
Long-form sentiment detection, where a shift in tone occurs gradually
Ticket volume forecasting, based on patterns in historical interaction data over days or weeks
Churn prediction, by analyzing sequences of user behavior leading up to a drop-off
What are some LSTMs' pros and cons?
While LSTMs are more capable than RNNs for handling long-range dependencies, they’re still computationally intensive and slower to train and scale compared to newer models like transformers. However, for moderate-length sequences and structured time series data, LSTMs remain a strong choice.
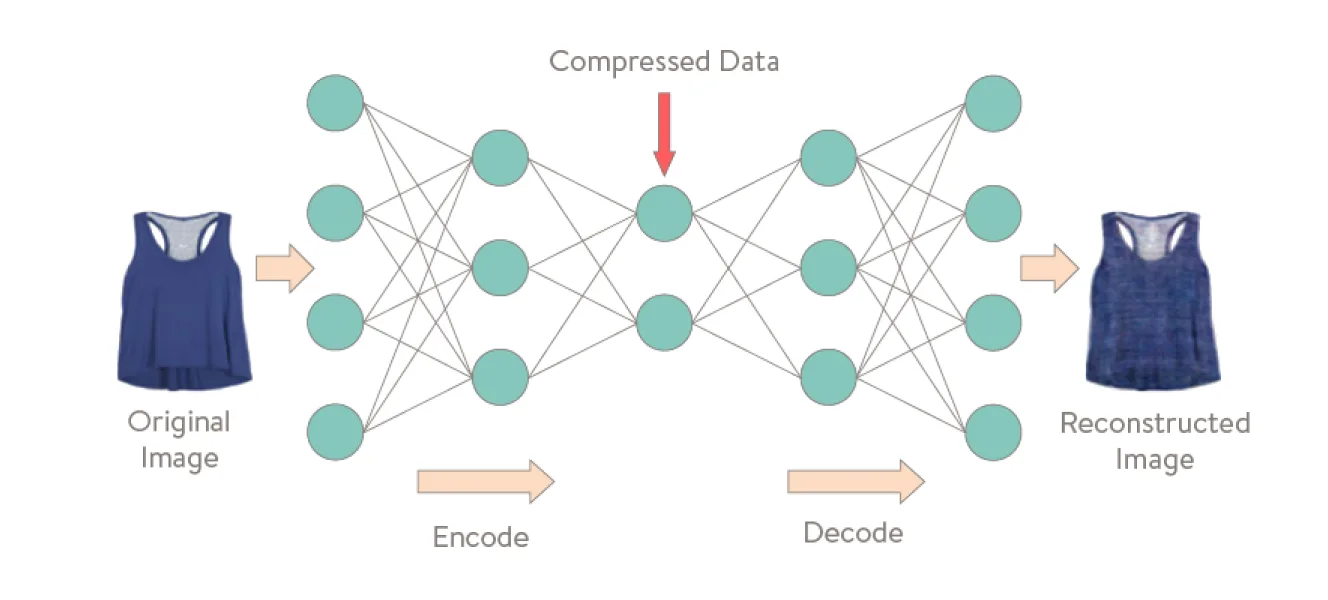
Autoencoders
What are autoencoders?
Autoencoders are unsupervised neural networks that learn to compress unlabeled input data and decode it back into its closest original form. This process allows the encoder to extract the data's most essential features and discard noise or redundancies.
What are autoencoders' use cases?
As a result, autoencoders are often used for:
Denoising blurry images or chat transcripts by filtering out repetitive or irrelevant message patterns
Compressing long-form content, such as meeting transcripts or support logs
Extracting key features from user interactions for use in downstream models
What are autoencoders' advantages?
Autoencoders are relatively simple to implement and train because they use a straightforward architecture—just an encoder and decoder—and are trained with standard backpropagation to minimize reconstruction loss. They don’t require labeled data, complex objectives, or adversarial setups like GANs. Their compression capability is also the foundation structure of large language models that can generate new content from the compressed content that preserves the essential information. Their compression capabilities make them ideal for classification tasks, anomaly detection, storage reduction, and transmission time reduction.
What are autoencoders' disadvantages?
Autoencoders have limitations that businesses should understand. If not properly tuned, they can overfit—meaning they memorize training data rather than learning patterns that generalize to new inputs. This reduces their usefulness in real-world scenarios. In more complex datasets, they may miss subtle relationships and instead just copy inputs without understanding their structure. Deeper models also demand heavy computational resources, which can make training slow and expensive. As a result, autoencoders work best for simpler tasks like noise removal or compressing data, not for high-stakes decision-making or tasks requiring deep reasoning.
Variational autoencoders (VAEs)
What are variational autoencoders?
VAEs are the technology behind what we commonly refer to as generative AI. They are models that can produce realistic images, conversations, or audio. While similar to autoencoders in capabilities, VAEs introduce a probabilistic element that allows them to go beyond data reconstruction and create variations.
What are variational autoencoder use cases?
This makes VAEs particularly effective for tasks that aim to reconstruct, augment, or subtly alter data while preserving its core features. They're also well-suited for identifying anomalies by flagging data that doesn’t conform to the learned distribution.
VAEs can be used for:
Reconstructing messages that have been distorted, redacted, or corrupted
Detecting anomalies in chat logs that may indicate edge cases, errors, or fraud
Generating synthetic message scenarios for testing or simulation without exposing real data
What are autoencoders' pros and cons?
While powerful generative models, VAEs can sometimes produce blurry or low-resolution outputs when creating images. They also require careful tuning to balance reconstruction accuracy with the variability introduced by the sampling process. Still, VAEs offer a compelling balance of efficiency and generative power for many structured and semi-structured data tasks.
Generative adversarial networks (GANs)
What are Generative adversarial networks (GANs)?
GANs are a class of generative models that involve two competing neural networks:
A generator that creates synthetic data from scratch. So fake images, videos, or audio.
And a discriminator that evaluates whether the data created looks real or fake by comparing it to the real image in the dataset.
This adversarial training allows GANS to train themselves. The process pushes both models to improve over time, resulting in increasingly realistic output from the generator and the discriminator's ability to learn the difference between real and generated data.
What are GANs' use cases?
Because GANs learn to generate new content that mimics patterns in the training data, they’re particularly effective for creating images, audio, or synthetic data that looks convincingly real, even when the input data is limited or imperfect. That data can then be used to train machine learning models. Very meta!
In customer experience and messaging contexts, GANs can be used for:
Creating synthetic training data when real data is scarce or privacy-restricted
Generating personalized avatars, stickers, or backgrounds for messaging interfaces
Exploring content customization and visual branding in creative environments
What are GANs’ pros and cons?
While GANs are easy to set up since they use unlabeled data for the most part, they can be challenging to train. Models may suffer from instability if the generator endlessly combats the discriminator or undergoes “mode collapse,” where the generator produces a narrow range of outputs. They also require double the computing power and lack fine-grained control over the output since they don’t have an explicit conditioning mechanism and use random noise vectors as input.
As a result, GANs are powerful but finicky. That’s why they are often used for research or artistic generation rather than scalable, real-time production systems.
Deep Q-networks (DQNs)
What are Deep Q-networks (DQNs)?
DQNs combine reinforcement learning with deep neural networks to help systems learn optimal actions through interaction and feedback.
How do Deep Q-networks work?
This deep learning model uses a Q-function that estimates the expected cumulative reward it will receive starting from a given state and then following the best strategy to achieve a goal.
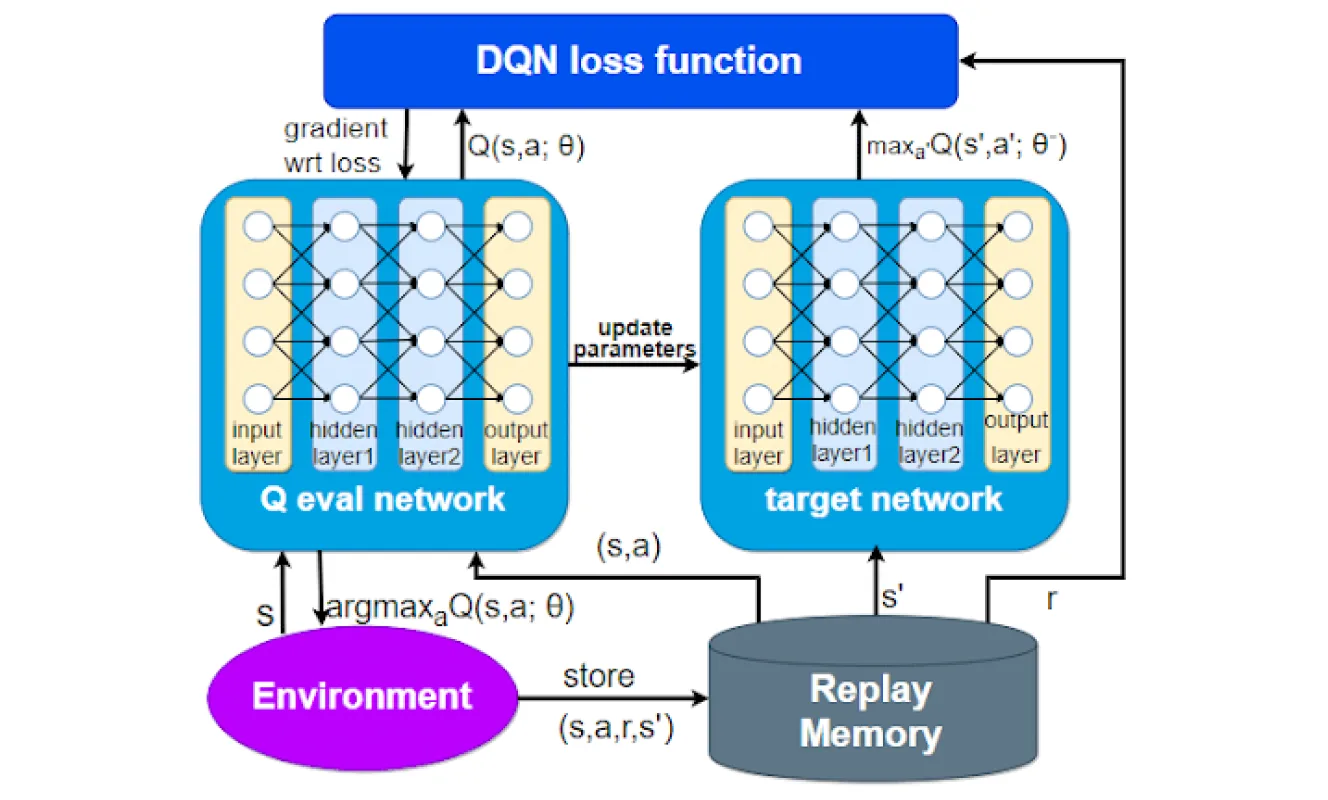
What are DQNs good for?
This rewarding technique allows DQNs to improve decision-making over time by exploring actions, receiving rewards (or penalties), and adjusting accordingly. They’re particularly well-suited for dynamic environments where conditions evolve and the system must adapt.
Specifically, DQNs excel at:
Optimizing dialog flow to determine the best next action in conversations to maximize user satisfaction.
Dynamically adjusting messaging strategies, such as timing or content sequencing
Learning ideal intervention points (e.g., when to escalate from bot to human agent) based on historical interactions
What are DQNs’ limitations?
DQNs have limitations. While powerful in interactive settings, DQNs come with challenges. They require careful reward shaping, large volumes of interaction data, and significant training time to reach optimal performance. Poorly designed environments or sparse rewards can lead to slow or unstable learning. Simpler or more controlled models may be more practical for use cases with limited feedback signals or high-risk decision-making.
Diffusion models
What are diffusion models, and how do they work?
Diffusion models are a class of generative AI models that create new data—typically images—by learning to reverse a process of gradually adding noise to training samples. In the forward diffusion phase, Gaussian noise is incrementally added to clean data until it becomes pure noise. Then, during the reverse process, the model learns how to denoise that noise step by step, effectively generating new, realistic samples from scratch. Unlike GANs, which rely on adversarial training, diffusion models optimize a denoising objective that leads to greater training stability and sample diversity.
What are diffusion models' use cases?
Diffusion models have rapidly become the go-to architecture for state-of-the-art image generation, powering tools like DALL·E 2, Midjourney, and Stable Diffusion. They're widely used in,
Creative industries for AI-generated art
Marketing for rapid prototyping
Scientific fields like protein folding
Medical imaging where high-fidelity visual outputs are critical.
Some models even extend into audio generation and video synthesis.
What are the pros and limitations of diffusion models?
The strengths of diffusion models include exceptional image quality, strong mode coverage (avoiding mode collapse), and the flexibility to control and guide the generation process with techniques like classifier guidance. However, they come with trade-offs: diffusion models require significant computational resources, often needing thousands of denoising steps to generate a single image. They're also slower to sample from compared to GANs and, as recent research suggests, potentially vulnerable to security issues like data poisoning or model backdoors.
Transformer networks
What are transformer networks?
Transformers are the foundation of nearly all modern natural language processing (NLP) systems, including large language models (LLMs) like GPT, BERT, and T5. Unlike RNNs or LSTMs, which process data sequentially, transformers use a self-attention mechanism that allows them to simultaneously weigh the importance of different words in a sequence. This parallel processing makes transformers significantly faster and more scalable, especially on long or complex inputs.
How do transformers work?
Under the hood, many transformer models follow an encoder-decoder structure: the encoder transforms raw text into vectorized representations (embeddings), while the decoder uses those embeddings—along with past outputs—to predict the next word in a sequence. During pretraining, this often involves a fill-in-the-blank learning objective, where the model learns to guess missing words or masked tokens based on context. This allows it to build a rich understanding of language structure before any task-specific fine-tuning.
One of the most significant paradigm shifts introduced by transformers is the move from task-specific models trained on labeled data to large-scale pretraining on unlabeled text. Once pretrained, these models can be fine-tuned on relatively small datasets for a wide range of downstream applications—from summarization to classification to generation.
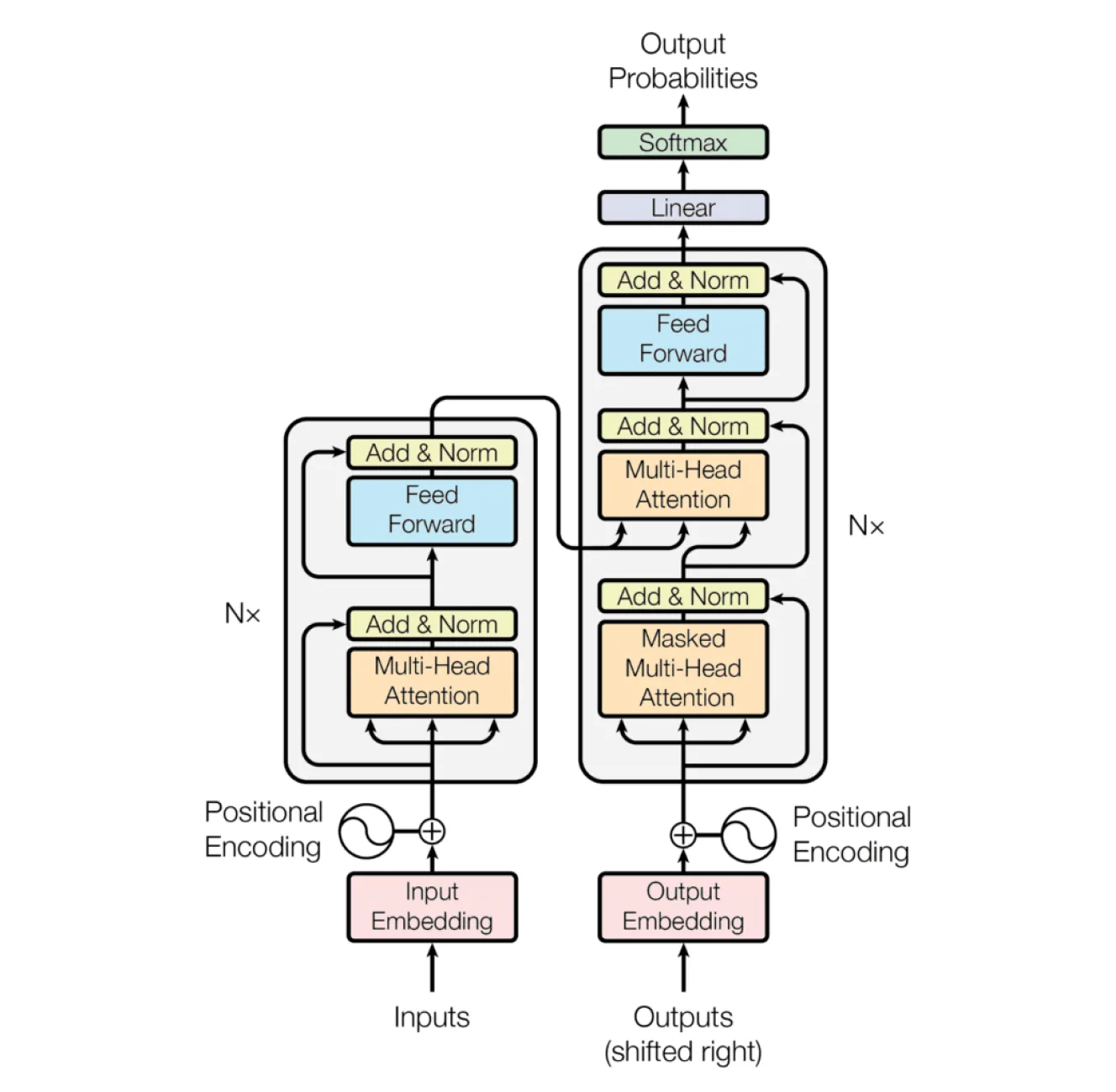
What are transformers' strengths?
Transformers are particularly effective at modeling long-range dependencies, determining word meaning based on context, and capturing subtle linguistic signals like tone, sentiment, or intent. Their versatility and performance make them the go-to architecture for a wide range of customer experience and communication use cases.
You’ll find transformer-based models driving:
AI concierges that understand user intent across multi-turn conversations and take appropriate actions
Language-aware routing that assigns tickets to the right agent or department
Real-time summarization of support threads or live chat sessions
Multilingual support, including translation, entity extraction, and intent detection
Message rewriting to adjust tone or clarity based on user behavior
What are transformers' limitations?
While transformers have become the gold standard for language tasks, they’re not without tradeoffs. Training and fine-tuning transformer models require significant computational resources, including powerful GPUs and large-scale datasets, making them more costly to develop and deploy than simpler architectures. Transformers also tend to require extensive hyperparameter tuning and can be prone to hallucinations if not grounded in a reliable context.

Delight customers with AI customer service
Choosing the right deep learning model for the job
Choosing the right deep learning model can make or break performance. But you don’t need to reinvent the wheel. Just match the right architecture to the type of data and task. Here is a quick reference table to help you identify the best fit based on your specific use case and goals.
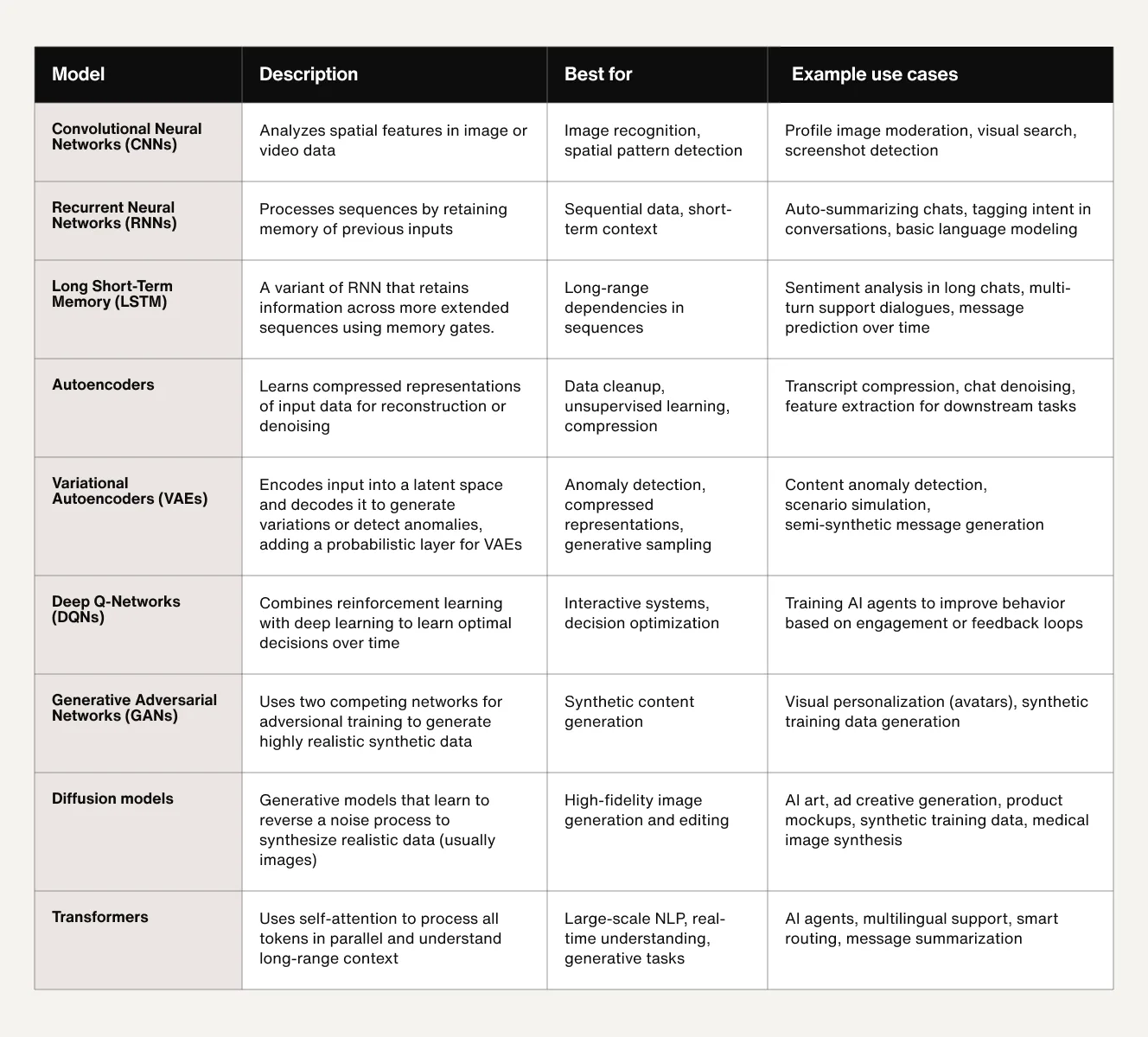
Deep learning use cases
Deep learning powers many of the intelligent systems available today. It enables AI software to recognize patterns, understand language, interpret images, and make decisions without being explicitly programmed to do so. Here are some of the most important deep learning use cases driving real-world innovation today.
Agentic AI and AI agents
Agentic AI refers to artificial intelligence systems that go beyond passive response and static robotic automation processes (RPAs). With access to tools, APIs, and contextual data, AI can interact with digital systems in real time to solve problems, delegate tasks, and coordinate workflows.
At the core of these systems are AI agents, autonomous programs that make decisions and take action to achieve specific goals. Each agent operates independently, but when multiple agents work together toward a shared objective, they form an agentic AI system.
AI agents go beyond standard conversational AI. They can identify the following best action, retrieve data from connected systems, and complete complex tasks. While human teams define the objectives and parameters, AI agents themselves manage how those goals are achieved. For example, an AI concierge could independently update an order or collect missing information for account verification.
Deep learning powers AI agents by using neural networks to model complex relationships in data. This allows AI agents to generalize from past interactions, predict user intent, and make decisions without relying on hardcoded rules.
Digital labor
While agentic AI represents the next frontier of autonomous, goal-driven systems, digital labor focuses on a more immediate and practical layer of automation. These AI systems are designed to complete well-defined tasks and streamline workflows with minimal input from developers or operators.
Digital labor tools use large language models (LLMs) and neural networks to understand context, extract information, and interact with APIs. For example, a deep learning model can identify key details in a customer conversation, gather missing fields from a knowledge base, and automatically update backend systems. This is often done using slot-filling techniques that help the model determine what inputs are needed and retrieve them as needed.
Digital labor plays a foundational role in enterprise AI strategies by improving operational speed and consistency. Rather than hard-coding every process, business teams can use no-code or low-code tools to create AI standard operational procedures (AI SOP) in plain language. These systems can be trained to handle repeatable tasks such as updating CRM records or sending follow-up messages.
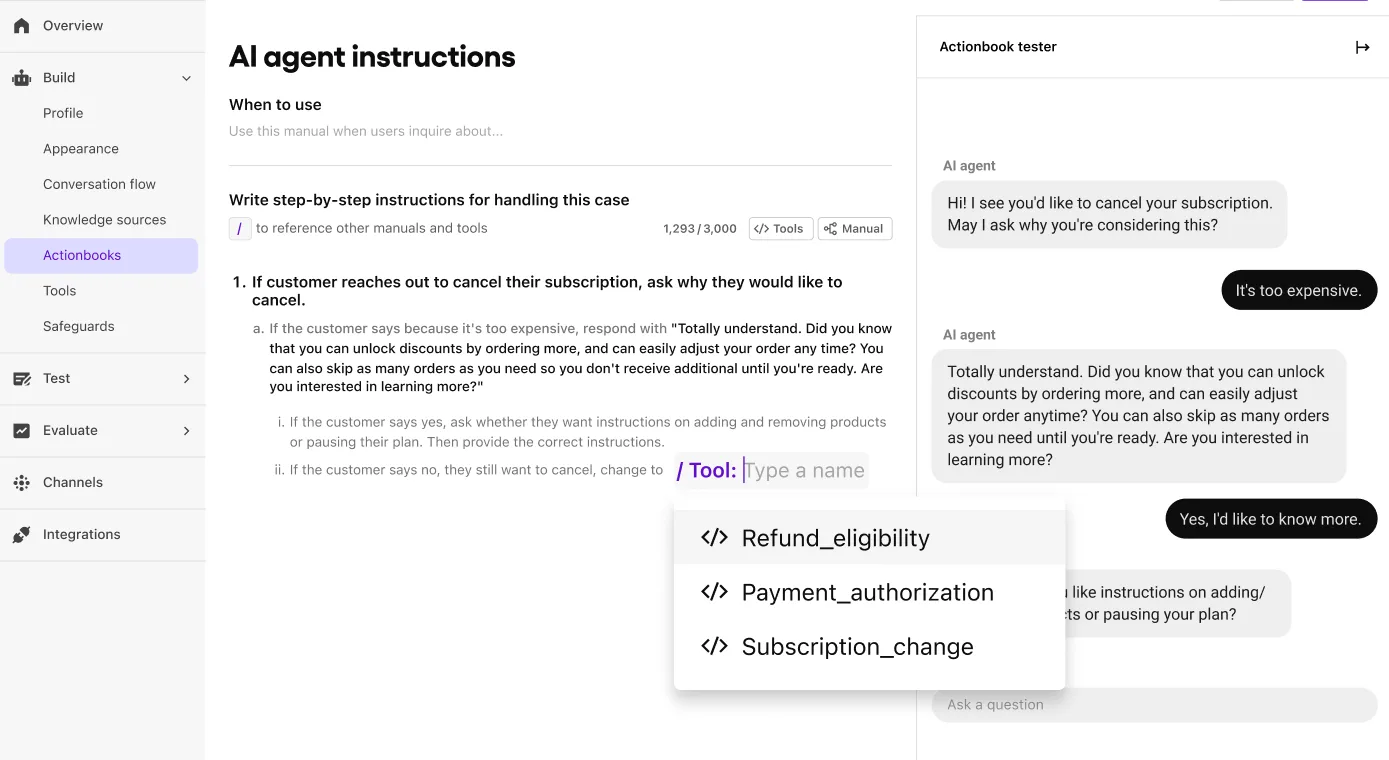
Application modernization
One of the most valuable applications of deep learning is accelerating application modernization. When paired with large language models (LLMs), deep learning makes it possible to quickly generate and transform code in ways that were previously time-consuming and manual.
Traditionally, refactoring legacy code or translating between programming languages required developers to manually rewrite sections of code, a process that could take days or even weeks. However, with deep learning-powered tools, developers can now input a plain language prompt and receive functional code in return.
These models, trained on massive open-source codebases, leverage neural network architectures like transformers to analyze programming patterns and understand the context of code. This enables them to generate context-aware code suggestions, auto-complete functions, or even rewrite entire blocks of code across different languages and frameworks.
This approach saves time. It also helps teams close skill gaps and clean up outdated code, making it easier to modernize systems efficiently, especially when working with legacy codebases written in less common languages.
Natural language processing (NLP)
Natural language processing (NLP) is a branch of AI that enables machines to understand, interpret, and generate human language. Deep learning has significantly advanced the power and flexibility of NLP models, allowing them to move beyond simple keyword detection to understand nuance, context, and emotion at scale.
Modern NLP systems can now:
Detect user intent from freeform messages
Analyze sentiment and emotional tone
Extract key information such as dates and product names
In customer support, these capabilities power dynamic routing, auto-tagging, and escalation detection. For example, a model might detect growing frustration across multiple replies and prioritize the conversation for a human agent before escalation occurs.
Deep learning enables these models to improve continuously as they’re exposed to more data, including raw, unlabeled data. Over time, they learn to handle ambiguity better, adjust to language patterns, and personalize responses based on conversation history.
Speech recognition
Deep learning has advanced automatic speech recognition (ASR), allowing machines to transcribe and understand spoken language with remarkable accuracy. Unlike earlier ASR systems, deep learning models don’t struggle to detect speech in the presence of background noise, varied accents, or shifting tones.
This technology is foundational for voice-driven interfaces, powering everything from virtual assistants to meeting transcription tools. In enterprise environments, it enables new models of communication and accessibility. For example, deep learning models can help turn voice notes into structured data, generate searchable conversation logs, and support multilingual voice interactions.
As models gain exposure to more varied speech patterns and usage scenarios, they become more robust. This enables intelligent support flows that can detect keywords, flag emotional cues, and integrate seamlessly with other AI systems or agentic workflows.
Computer vision
Computer vision is a subset of artificial intelligence that enables systems to analyze and interpret visual information from images and video with speed and precision. Deep learning allows these models to identify faces, detect inappropriate content, extract text from images, and recognize objects in complex scenes.
These capabilities are already being deployed across industries:
Healthcare – Deep learning models are helping radiologists detect tumors and anomalies in medical scans faster and more accurately. Analyzing thousands of annotated images, these systems learn to identify subtle patterns that human eyes may miss. This technology leads to earlier diagnoses and better patient outcomes.
Retail and e-commerce – Visual search tools use convolutional neural networks (CNNs) to help customers find products by uploading photos. Deep learning also powers smart recommendations based on product appearance and supports inventory management through real-time image recognition in warehouses and fulfillment centers.
Content moderation and social platforms – In communication apps and online communities, deep learning-powered vision models help flag unsafe or inappropriate content, verify profile images, and assist with accessibility features like image-to-text conversion.
Generative AI
Generative AI (Gen AI) uses deep learning to create new content based on patterns learned from large datasets. Tools like ChatGPT have made this technology widely accessible, enabling systems to write summaries, compose emails, generate responses, or draft entire documents.
In messaging and support contexts, generative AI helps automate parts of customer interactions, produce more empathetic replies, and create personalized follow-ups that feel natural and human.
But its capabilities go beyond generating language. Multimodal generative models can process and create across formats, including text, image, audio, video, and social media content. This makes these models useful for branded content generation, visual asset creation, and intelligent document generation.
At the enterprise level, Gen AI can accelerate content workflows, scale personalized communication, and power AI agents capable of responding to customers across languages and contexts. When combined with business-specific data and real-time inputs, these models can generate more accurate, tailored outputs without requiring extensive manual scripting or rule-building.
Personalization and recommendation engines
Deep learning excels at modeling complex user behavior and preferences over time. Analyzing large volumes of interaction data can generate highly personalized recommendations in real time.
These systems power more than just product suggestions or content feeds. For example, in customer support contexts, they can dynamically adjust reply prompts, recommend relevant knowledge base articles, and prioritize specific workflows based on user history, sentiment, or intent.
As users engage with the model, it continues to refine its understanding to improve the relevance and timing of future suggestions. This adaptability is key for use cases like multilingual personalization or multi-device support.
Workflow orchestration
Deep learning enables dynamic automation by allowing systems to analyze message content, infer context, and make decisions in real time. As these systems scale, they enable AI orchestration across tools and departments.
For instance, a single customer interaction can initiate a coordinated series of actions. The system might update CRM fields, assign a ticket to the appropriate human agent, extract key details for reporting, and route the case based on urgency or sentiment.

Harness proactive AI customer support
Real-world applications of deep learning across industries
While deep learning can be applied across nearly every sector, its real power lies in how it adapts to the specific challenges and workflows of different industries. From personalized customer support in SaaS to patient communication in health tech, deep learning enables faster, smarter, and more humanlike interactions.
Customer support and CX
Deep learning has become essential for improving customer experience in digital-first businesses. For example, it powers AI concierges that go beyond simple chat interactions to understand customer intent, detect sentiment, summarize long conversations, and escalate complex cases when needed.
These agents can auto-tag tickets, route requests to the right team, and personalize responses based on prior interactions. By automating routine support tasks and surfacing insights in real-time, deep learning-enabled agents help reduce response times, improve satisfaction scores, and deliver 24/7 support without overwhelming human team members.
Healthcare and health tech
In healthcare and health tech, deep learning powers the tools and platforms that clinicians and care teams rely on every day. It enables technologies like automatic transcription of clinical conversations, AI-based symptom checkers, and intelligent triage assistants that help route patient inquiries to the right provider.
On digital health messaging platforms, deep learning models can analyze language patterns to flag urgent cases or detect when critical information is missing. These capabilities help healthcare organizations communicate more quickly, accurately, and securely, while still meeting strict compliance requirements.
Financial services
In banking and fintech, deep learning powers the systems that help teams detect fraud, automate support, and personalize client communication. These models drive tools that can summarize customer messages, generate auto-responses to common requests, and flag high-risk or high-value interactions for faster handling.
Deep learning also supports document classification and regulatory compliance workflows, reducing manual effort and increasing processing speed. For financial institutions, these AI-driven capabilities enable faster, more accurate, and more secure client service.
Education and EdTech
Deep learning powers the tools that make learning more personalized and interactive in online learning platforms and educational apps. It enables real-time feedback, adaptive learning paths, and intelligent tutoring systems that respond to a student’s progress.
Deep learning models can also help transcribe lectures, summarize dense reading materials, and generate quiz questions tailored to individual learning styles. These capabilities allow EdTech tools to deliver more engaging, responsive, and individualized experiences, especially in asynchronous or large-scale learning environments.
E-commerce
In e-commerce, deep learning powers the systems that personalize and streamline the customer journey, from product discovery to post-purchase support. These models drive product recommendation engines, dynamic pricing tools, personalized marketing campaigns, and virtual shopping assistants that guide users toward the right items.
Deep learning enables sentiment analysis on customer reviews, automates return and exchange workflows, and generates smart responses to common support questions. By embedding deep learning into these tools, e-commerce businesses can deliver a faster, more tailored, and more scalable shopping experience.
Travel and hospitality
In the travel and hospitality industry, deep learning powers the tools that enable more personalized, efficient, and multilingual guest communication. From booking to check-out, these AI-powered tools help create smoother, more responsive guest experiences.
Airlines and booking platforms use deep learning-powered systems to automate itinerary changes, predict service disruptions, and deliver dynamic offers based on traveler behavior. Hotels can also enhance guest messaging platforms with deep learning to analyze feedback in real time, detect sentiment, and surface upsell opportunities at just the right moment.

Empower your support agents with AI
Benefits of using deep learning
Here are the key benefits of using deep learning and why they matter for communication-focused teams.
Real-time personalization at scale
Deep learning models can analyze user behavior, language patterns, and historical interactions to deliver more relevant, timely responses. Whether it’s suggesting a smart reply in chat or auto-filling a support ticket based on intent, these systems adapt instantly to each user. That means every interaction can feel personal, even when you're serving thousands at once.
Better understanding of language and context
Compared to traditional machine learning, deep learning excels at parsing nuance. It captures tone, intent, sentiment, and meaning in ways that rule-based systems can’t. This makes it ideal for live chat, support, or moderation systems that need to understand not just what a user said, but what they meant.
Automated workflows without human bottlenecks
Deep learning can power everything from routing messages to the right team to automatically tagging incoming conversations. By training models on historical data, businesses can reduce time spent on repetitive tasks and free up human agents for higher-impact work.
Continuous learning from user behavior
Because deep learning models improve over time, they can adapt to new phrases, trends, and user behavior without needing to be reprogrammed. For example, if your customers start using new slang or product terms, your model can learn to recognize and respond without manual retraining.
Multimodal intelligence
Deep learning handles multiple data types, including text, audio, and images. This makes it possible to moderate image uploads, analyze tone in voice messages, or combine visual and verbal signals in one pipeline. For messaging apps and communication platforms, this unlocks smarter safety and compliance features.
Reduced operational costs
By automating tagging, moderation, classification, and even conversation handling, deep learning reduces the need for large human teams. And as models improve, they help deliver faster resolution times, lower average handling costs, and higher satisfaction, without needing to scale headcount at the same rate.
Challenges of using deep learning
Deep learning has expanded what AI can do. But that power comes with tradeoffs. Here are some of the key challenges of using deep learning.
High data requirements
Deep learning models rely on massive amounts of high-quality data to perform well. If your dataset is too small or full of noise, errors, or gaps, your model may learn the wrong patterns. This can be especially problematic in communication platforms, where conversations vary by tone, culture, and context. For example, a model trained primarily on English-language data might misinterpret regional slang or multilingual support tickets.
Costly preprocessing and storage
Before training, your data needs to be cleaned, formatted, balanced, and possibly labeled. For companies with large volumes of chat logs, transcripts, or user-uploaded content, preprocessing often requires custom pipelines and significant cloud storage capacity.
Compute-intensive training
Training deep learning models requires powerful hardware, typically GPU clusters or TPU instances. Without the proper infrastructure, training can be prohibitively slow or expensive. Even when offloading to cloud services, costs can add up quickly, especially when experimenting with different architectures or hyperparameters.
Latency in real-time systems
Once deployed, deep learning models can be slow to run, especially if they’re large or not optimized for inference. In real-time messaging systems, even minor delays can negatively impact user experience. If your content moderation, reply suggestion, or routing engine lags by half a second, that might be enough to frustrate users or bottleneck your support team.
Model drift and maintenance
A model trained today may not work as well six months from now. Language evolves, product names change, and customer behavior shifts. Without ongoing monitoring and retraining, deep learning models can gradually lose accuracy. This problem, called model drift, often goes undetected until user complaints start rolling in.
Bias in training data
AI models are only as fair as the data they’re trained on. If your dataset contains historical biases—whether in tone, representation, or labeling—your model may amplify them. This is especially critical in support tools, where biased predictions can lead to unequal treatment or offensive outputs. Preventing this requires both diverse training data and regular audits.
Lack of explainability
Deep learning models don’t always reveal why they made a decision. That’s a problem when you need to justify a content flag, explain a routing decision, or debug a misclassification. Without built-in transparency, teams may struggle to answer questions from leadership, regulators, or users.
Risk of overfitting
Deep learning models can sometimes memorize the training data instead of learning patterns that generalize well. This means the model may perform poorly on new or unseen data, even if it shows high accuracy during training. Preventing overfitting typically involves using larger datasets, applying regularization techniques, and choosing evaluation metrics that reflect real-world performance.

Reimagine customer service with AI agents
Deep learning and the rise of AI agents
At Sendbird, we’re using deep learning to power AI agents for customer service. Our AI agent platform is built on Large Language Models that manage multi-turn conversations, understand context, and take meaningful actions.
These integrate directly with popular support software, combining machine and human intelligence to enhance performance, operational efficiency, and customer satisfaction (CSAT).
If you’re ready to move beyond static bots into intelligent and scalable AI customer service, our team can help you get there.
👉 Contact us.









