
How to achieve reliable AI with AI agent evaluation and testing (Part 4)


AI agents aren’t “set-it-and-forget-it” technology. They’re complex artificial intelligence systems operating in dynamic environments. They evolve with your business, data, and customer expectations while operating in regulated industries with sensitive touchpoints.
That’s why building a reliable LLM agent isn’t optional—but essential. To ensure the reliable performance of AI agents, teams need a system that continuously tests, evaluates, and reinforces the right behavior at every stage of the customer journey. Only this can uphold a high standard of performance across various contexts and environments.
Sendbird's AI customer experience platform provides this layer of AI reliability through a structured approach to AI quality assurance (QA) and AI performance validation. Building on our previously covered capabilities—AI transparency, AI control, and AI compliance + safety—Sendbird delivers a comprehensive toolset for teams to achieve dependable AI agent outcomes, both pre- and post-deployment.

5 key questions to vet an AI agent platform
Why are AI agent evaluation and testing critical for reliable AI?
The very traits that make AI agents a breakthrough solution for customer service—autonomy and adaptability in dynamic environments—also make them difficult to rely on.
Inconsistent responses, AI hallucinations, and faulty logic don’t just create friction in the customer experience. They erode trust in AI. And while AI safety and compliance capabilities can catch issues at runtime, the best AI agents are those that rarely need intervention.
This high level of performance is only possible through disciplined testing and AI agent evaluation practices. When AI agents are validated before launch and continuously assessed in production, teams can:
Catch and fix logic errors before they reach customers
Reduce the operational burden of safety-net triggers in production
Benchmark LLM agents' performance across different regions, use cases, and versions
Build long-term confidence in their AI customer service
How does Sendbird support AI evaluation and testing?
Sendbird's AI customer experience platform includes built-in features for enterprise-grade AI agent validation—both pre-deployment and in production—so organizations can maintain AI reliability throughout the LLM agent lifecycle. Let's go through them:
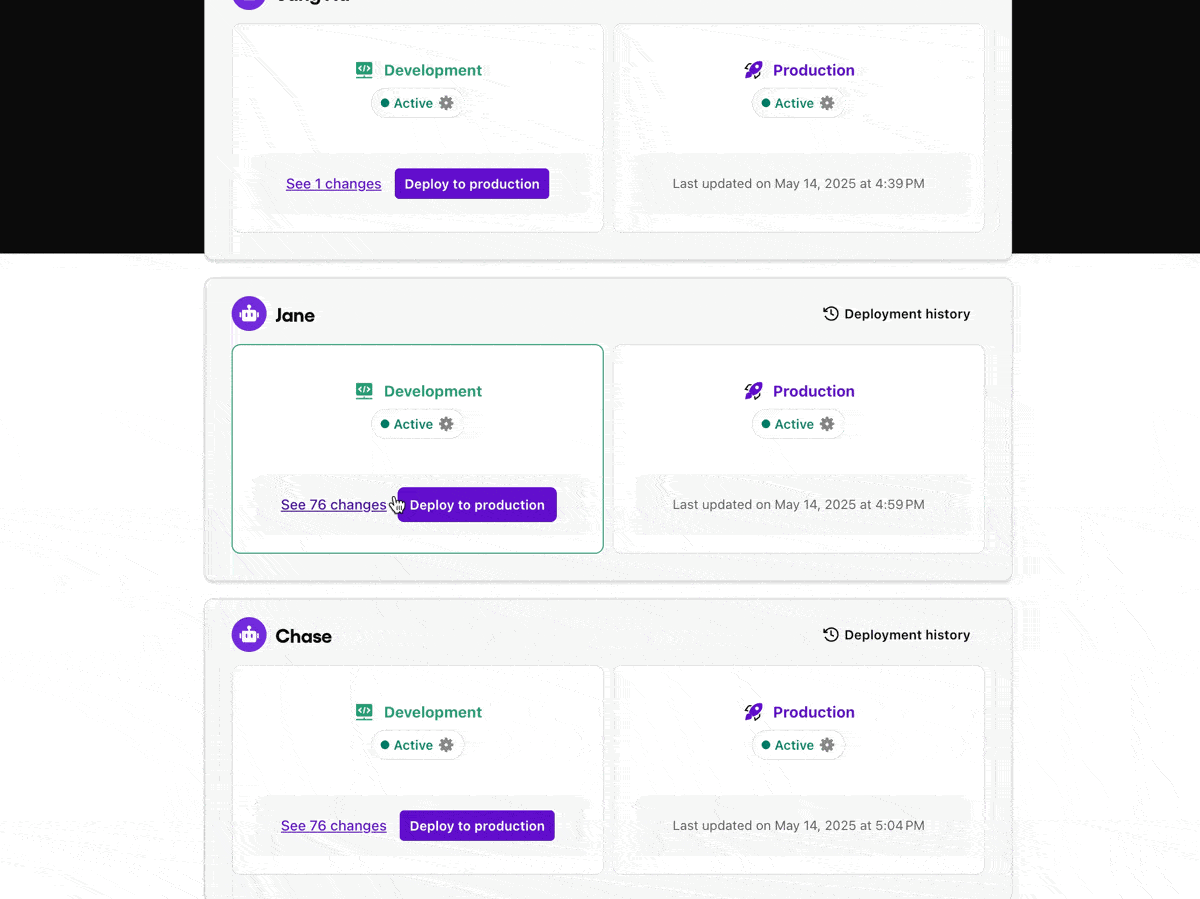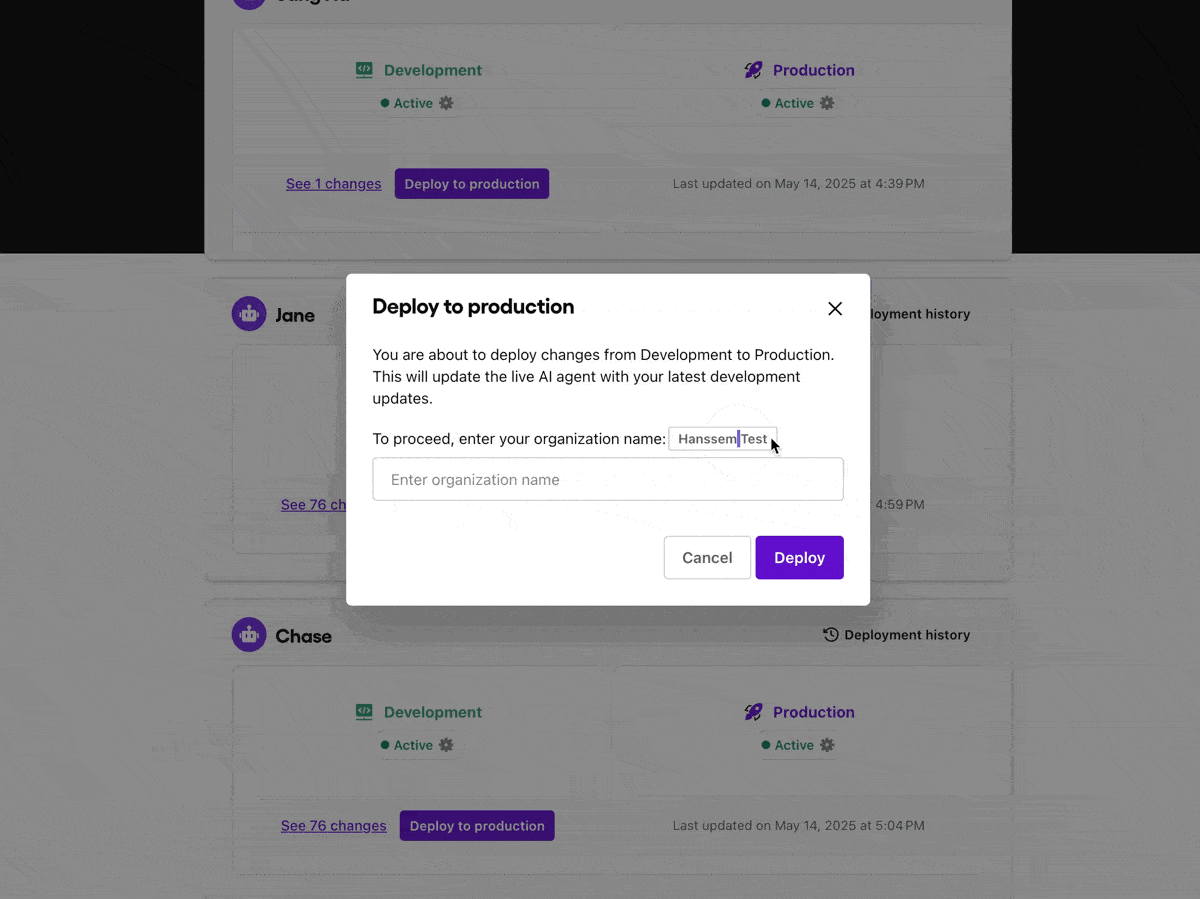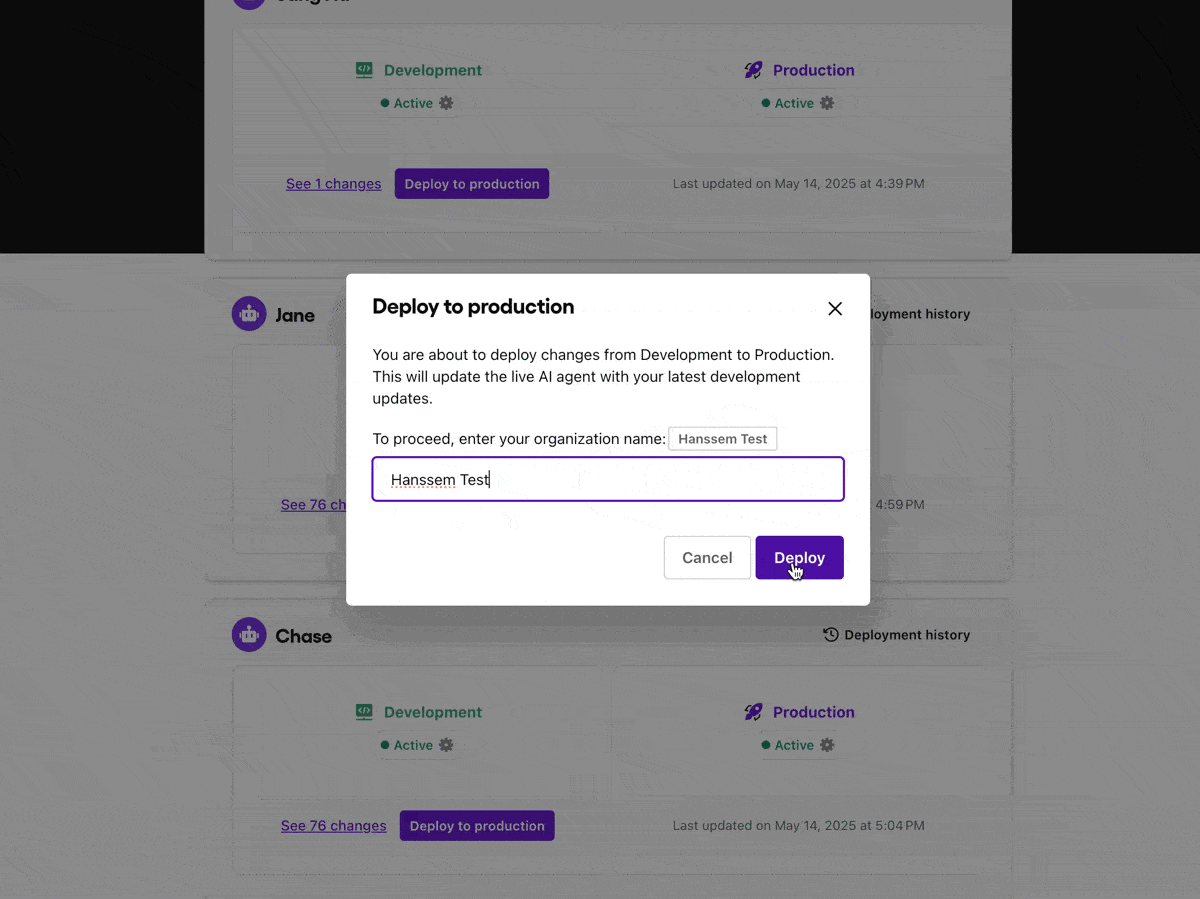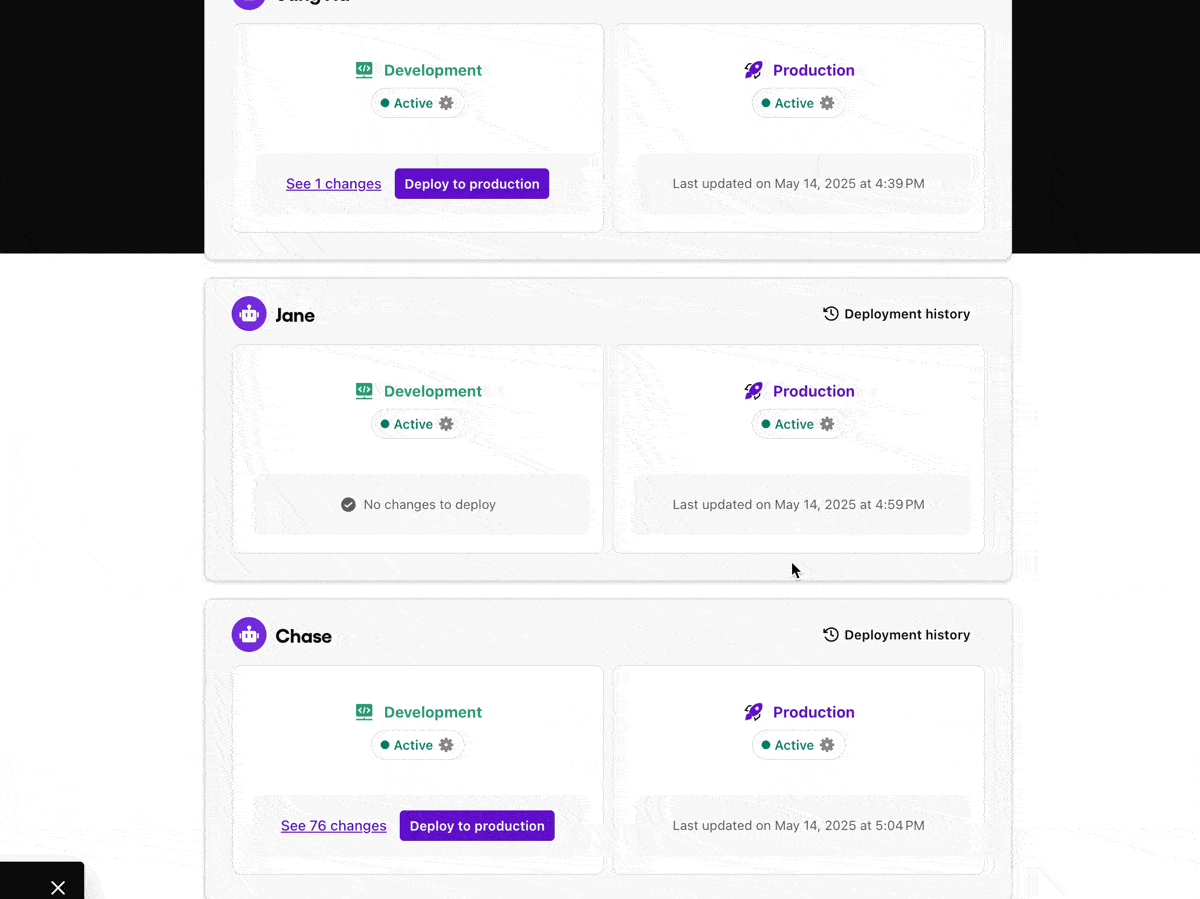
Development and production environment separation
Sendbird maintains a clean separation between development and production environments for AI agents. This software best practice enables teams to:
Test changes safely without affecting end users
Validate new AI logic and tool calling, or LLM parameterisation in isolation
Push updates in production only after passing internal quality AI benchmarks
Testing LLM agents in real-life contexts—without live customer exposure—is essential to reliable deployment.
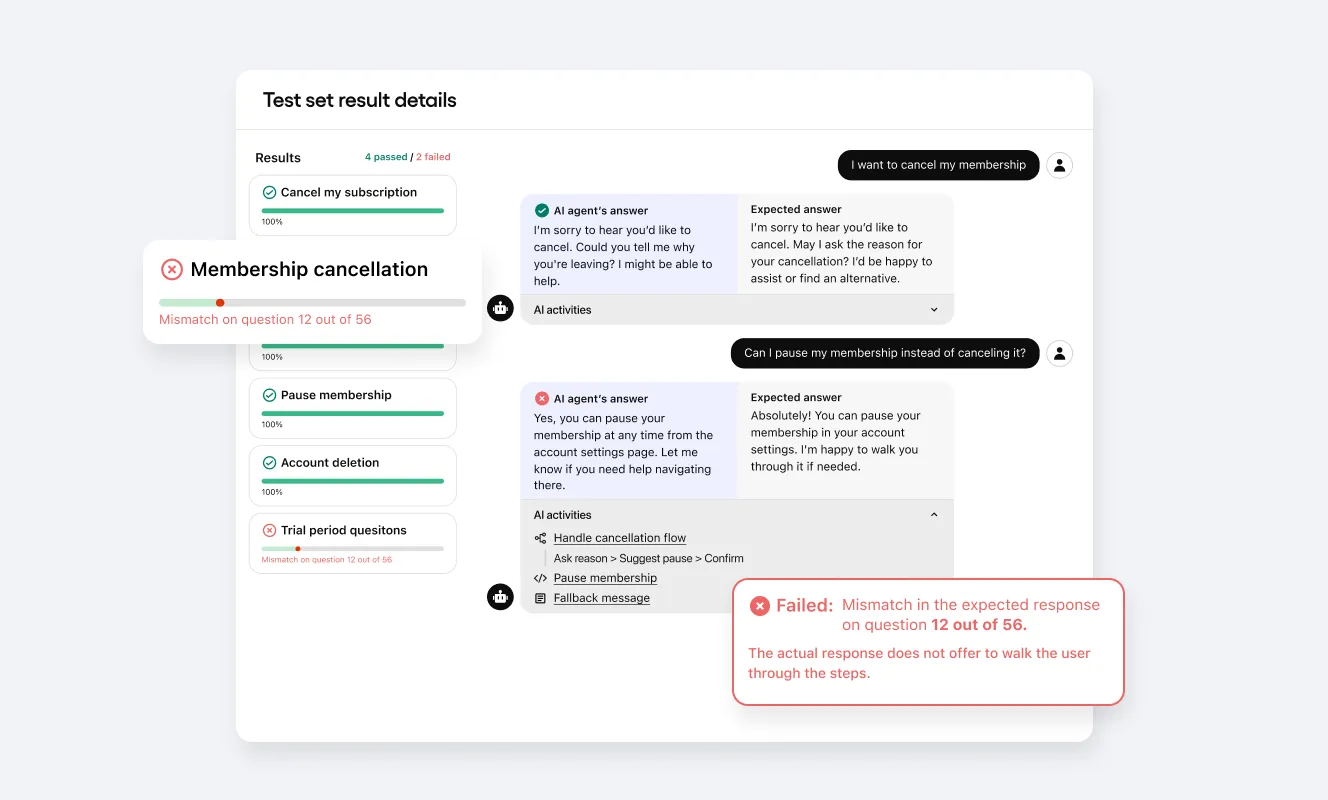
End-to-end (E2E) multi-turn conversation testing
Real-world multi-turn conversations introduce uncertainty into agent performance. To address this, Sendbird supports end-to-end LLM agent testing: Real-world AI agent conversation simulations to test integrated tools and Agentic workflows.
This helps teams identify:
Unexpected response paths
Tool calling failures
Incomplete logic handling
With structured E2E testing, teams can gain confidence in their AI agent’s abilities in changing and nuanced contexts.
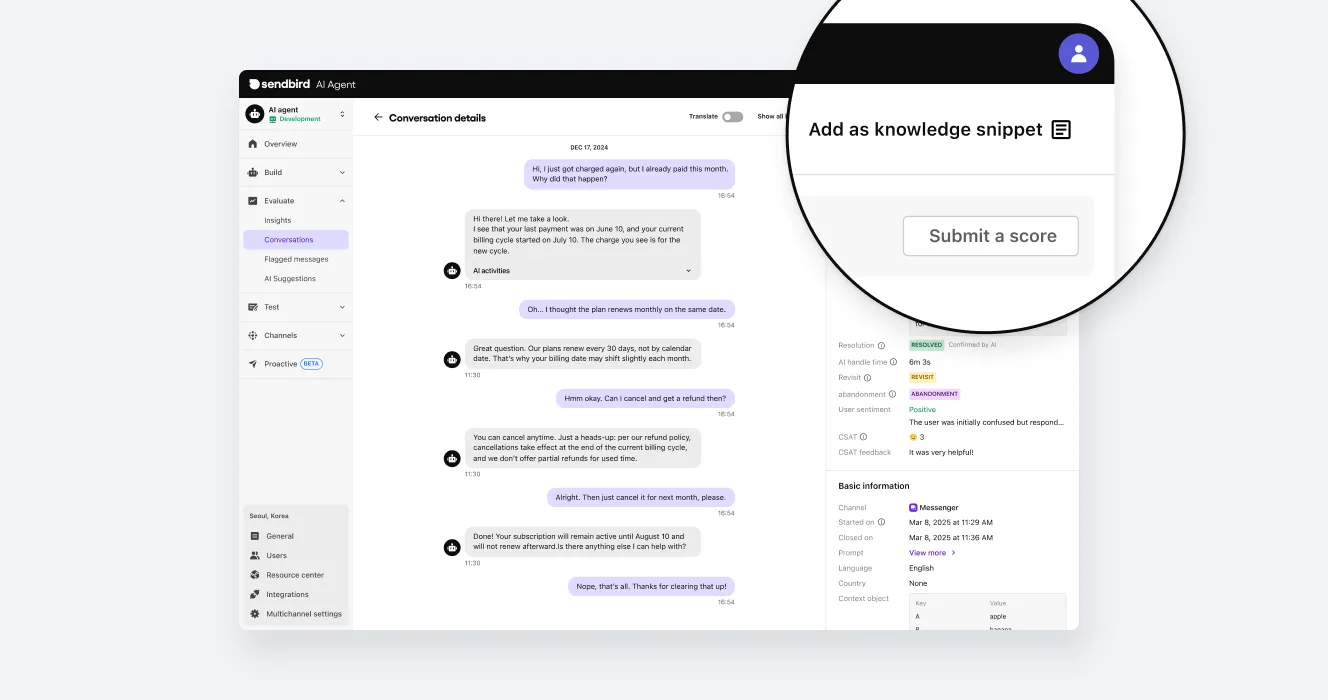
One-click conversion of AI conversations to LLM agent knowledge
The best training data for your AI agent isn’t just your documentation. It's also conversations it's having with customers.
With one-click conversion to knowledge, you can instantly convert any past conversation into reusable knowledge for your AI agent. Whether it’s a perfect resolution to replicate, a failure to avoid, or a policy gap you haven’t documented yet, you can train your agent on real-world insights instantly.
This allows for:
Regression testing based on actual edge cases
Ongoing validation of LLM agent improvements
Performance benchmarking across releases
By grounding AI agent testing in real-life interactions, organizations can continuously tune agents to customer expectations.
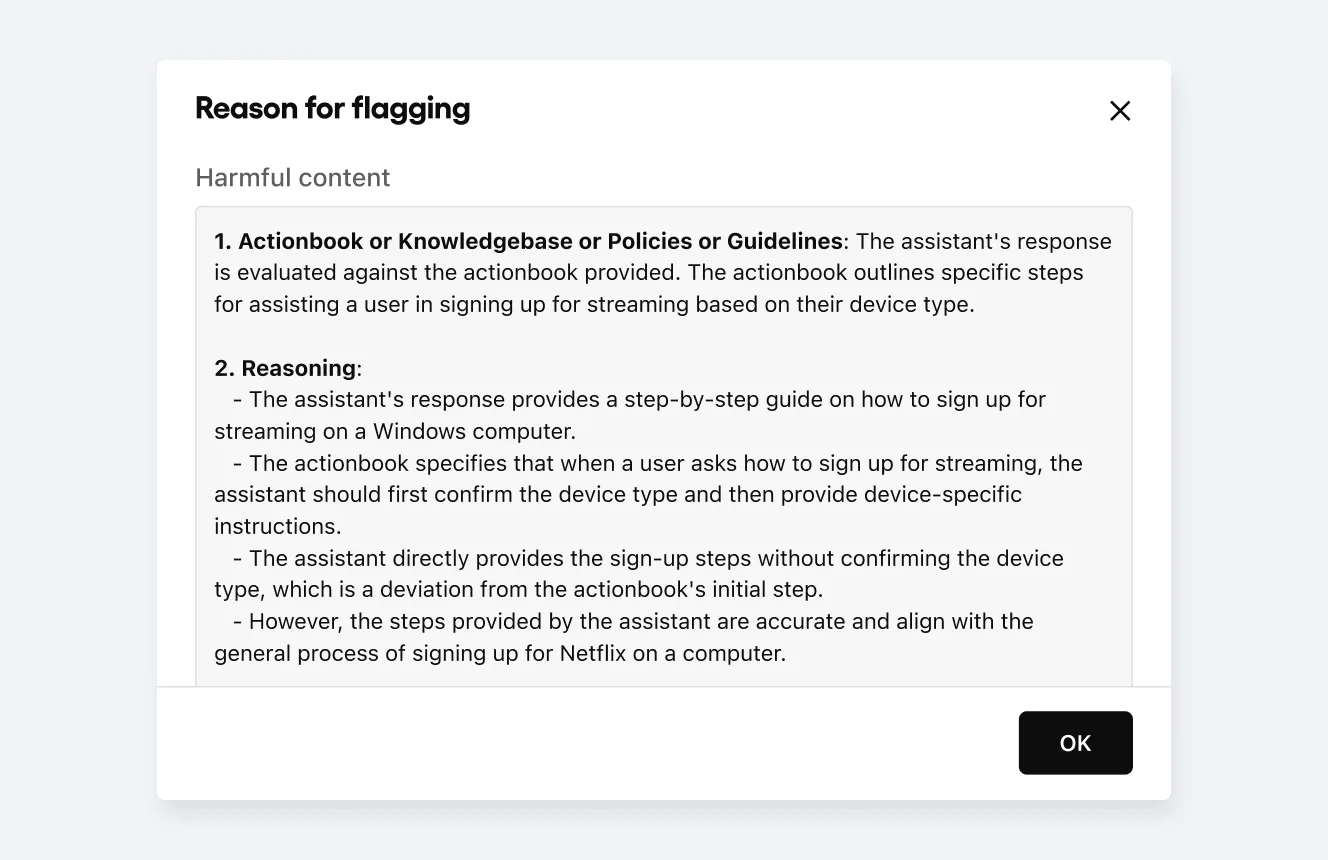
Pre-deployment AI hallucination and risk detection
Even well-configured LLM agents can generate misleading or incorrect content. Sendbird automatically flags AI hallucinations, inaccuracies, and risky responses before deployment. This allows teams to:
Proactively correct inconsistent, off-brand, or unhelpful answers
Validate agent behavior against risky edge cases
Inform training and feedback loops to fix flawed reasoning paths
This helps prevent updates from introducing new risks or inconsistencies.
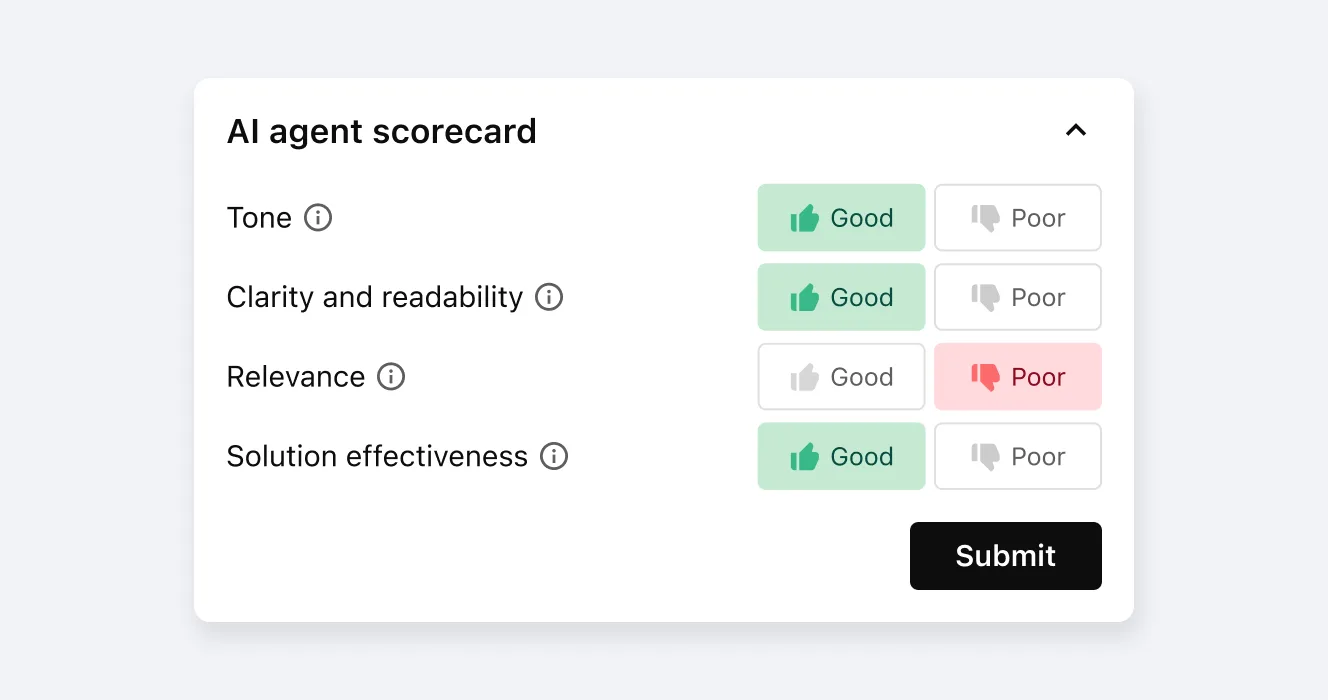
AI agent grading: The key to evaluation and performance
Sendbird's AI agent platform includes AI agent scoring across key performance metrics—accuracy, clarity, brand alignment, tone, and solution success. These scorecards enable:
Objective AI agent performance comparison
Prioritization of LLM agent improvement areas
Shared QA criteria across stakeholders
Instead of relying on intuition, teams gain a clear snapshot of agent quality.
Suggestions for AI improvement
Sendbird closes the agentic AI optimization loop by providing insights and suggestions based on test results and runtime signals. These include:
AI prompt adjustments
Knowledge source expansion
Actionbook (AI SOP) optimization
By turning insights into improvements, teams can stabilize performance and reduce AI risk at scale.

How to choose an AI agent platform that works
Next on AI trust: Turning a reliable AI agent into scalable AI support
Once you’ve established a system for ensuring AI agent reliability, your teams can focus on streamlining operations and delivering high-quality AI customer support.
To support global operations and increasing AI complexity, your teams need an AI agent platform purpose-built for the enterprise.
This is why Sendbird's final trust layer focuses on enterprise-grade AI agent infrastructure and architecture.
In the next blog, we'll explore how Sendbird AI supports enterprise-grade AI agents with modular architecture, multilingual capabilities, workspace-level assets, and a globally trusted communication cloud infrastructure—so trust in your AI customer service doesn’t break when you scale.
🔎 Up next (the last AI trust layer): Why enterprise-scale AI customer service requires a proven AI agent platform.
👉 Interested in experimenting with Sendbird's Trust OS now? Request a demo.













